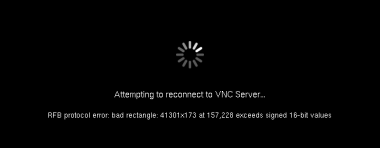
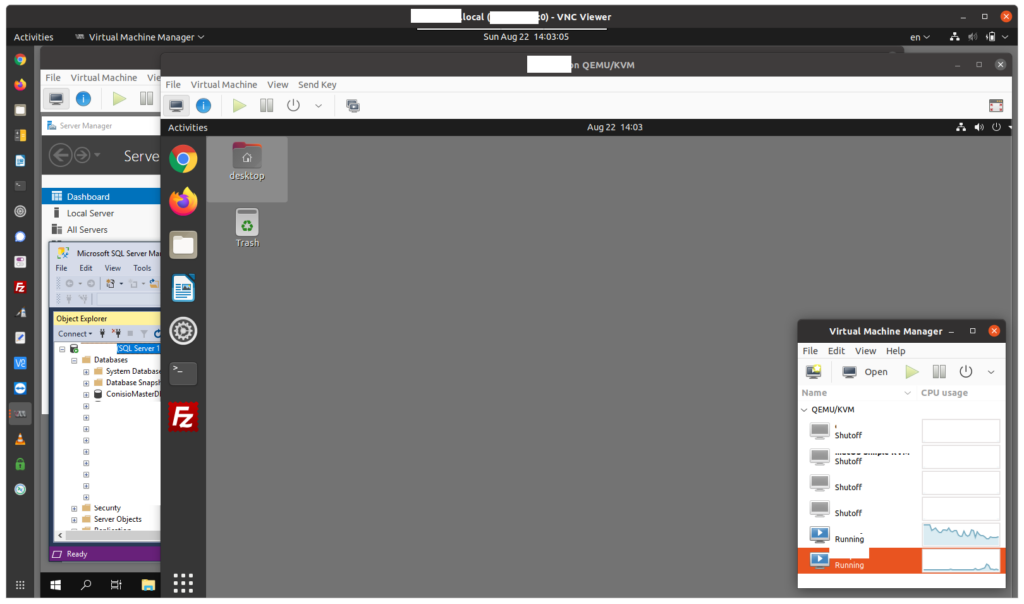
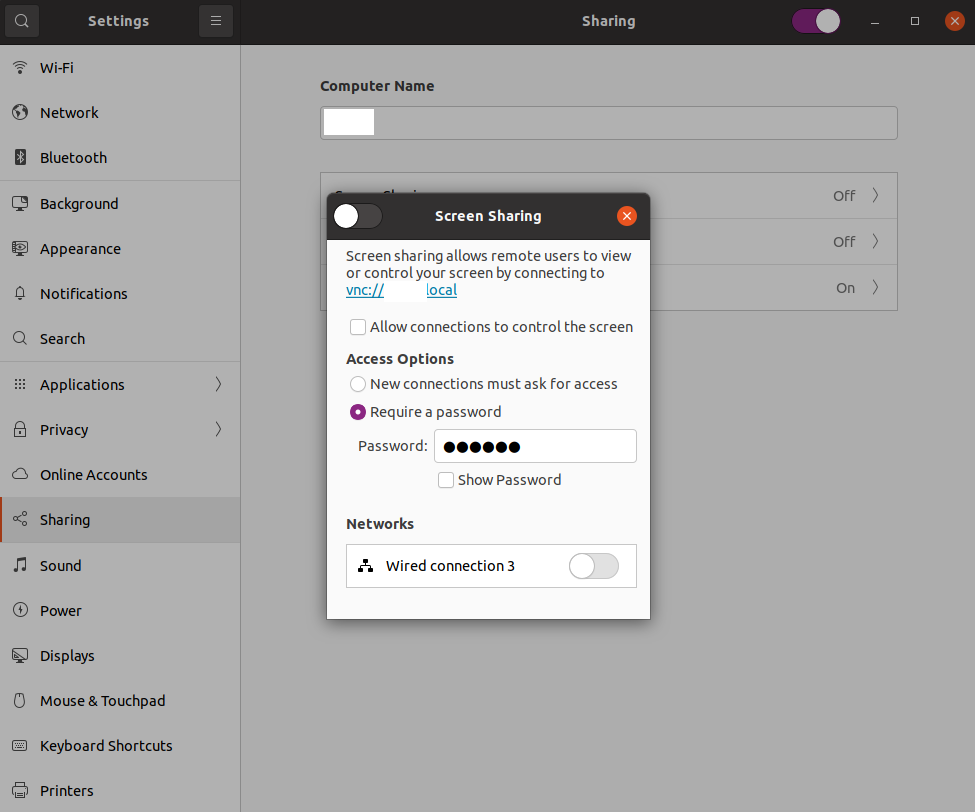
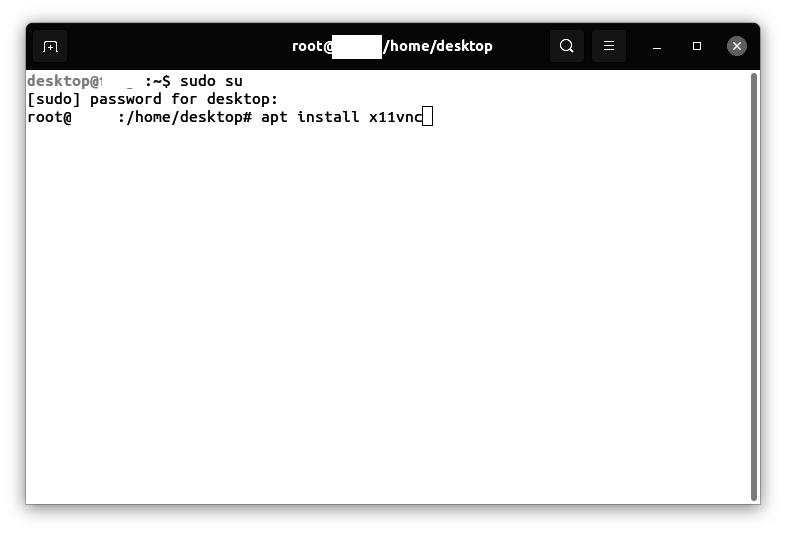
This procedure describes how to create a WordPress chatbot using FAISS for RAG and an external LLM API. We start by scanning the database of WordPress posts, to create a FAISS vector database. We then create an API wrapper that combines hinting information from the local FAISS database with a call to a remote LLM API. This API wrapper is then called by a chatbot, which is then integrated into WordPress as a plugin. The user interface for the chatbot is added to the sidebar of the WordPress blog by adding a shortcode widget that references the chatbot’s PHP, JavaScript, and cascading stylesheet (CSS) elements.
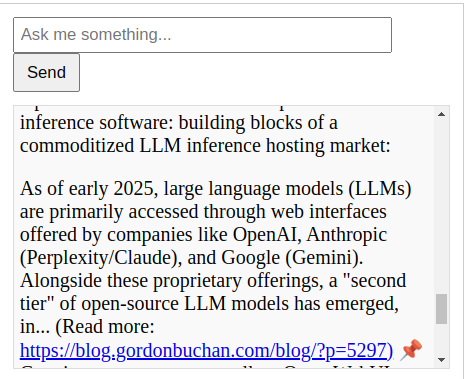
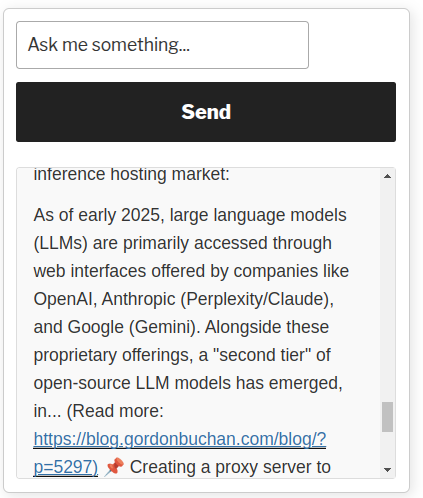
The chatbot accepts natural language queries, submits the queries to the RAG API wrapper, and displays results that contain the remote LLM API’s responses based on the text of blog posts scanned by the RAG system. Links to relevant blog posts are listed in the responses.
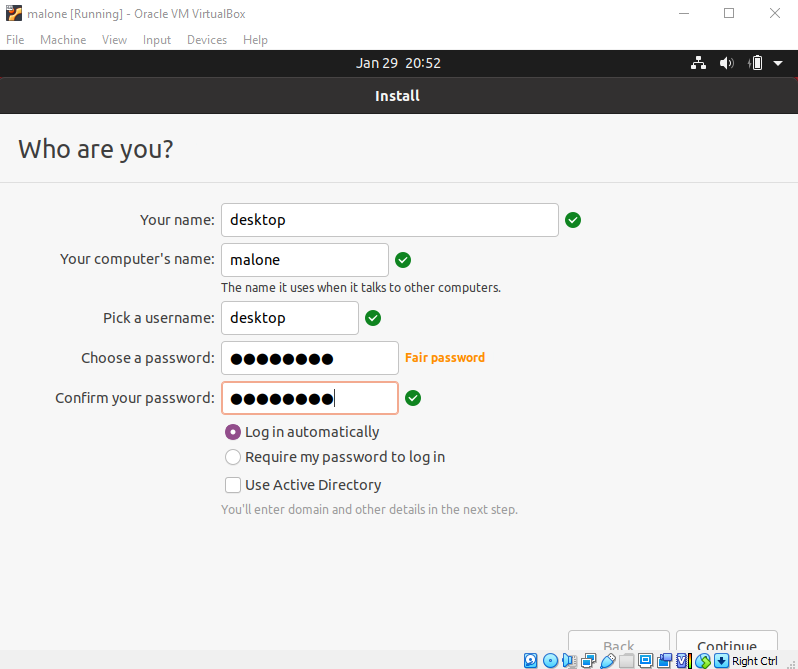
Using a recent Linux distribution to support Python 3.12 and some machine learning tools
In order to implement this procedure, we need a recent Linux distribution to support Python 3.12 and some machine learning tools. For this procedure we are using Ubuntu Server 24.04 LTS.
Using a server with relatively modest specifications
Most public-facing websites are hosted in virtual machines (VMs) on cloud servers, with relatively modest specifications. Because we are able to use an external LLM API service, we only need enough processing power to host the WordPress blog itself, as well as some Python and PHP code that implements the FAISS vector database, the RAG API wrapper, and the chatbot itself. For this procedure, we are deploying on a cloud server with 2GB RAM, 2 x vCPU, and 50GB SSD drive space.
import faiss
import numpy as np
import json
import os
import mariadb
from sentence_transformers import SentenceTransformer
from dotenv import load_dotenv
# MIT license Gordon Buchan 2025
# see https://opensource.org/license/mit
# some of the code was generated with the assistance of AI tools.
# Load environment variables from .env file
load_dotenv(dotenv_path="./.env")
DB_USER = os.getenv('DB_USER')
DB_PASSWORD = os.getenv('DB_PASSWORD')
DB_HOST = os.getenv('DB_HOST')
DB_NAME = os.getenv('DB_NAME')
# Load embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
# FAISS setup
embedding_dim = 384
index_file = "faiss_index.bin"
metadata_file = "faiss_metadata.json"
# Load FAISS index and metadata
if os.path.exists(index_file):
index = faiss.read_index(index_file)
with open(metadata_file, "r") as f:
metadata = json.load(f)
metadata = {int(k): v for k, v in metadata.items()} # Ensure integer keys
print(f"📂 Loaded existing FAISS index with {index.ntotal} embeddings.")
else:
index = faiss.IndexHNSWFlat(embedding_dim, 32)
metadata = {}
print("🆕 Created a new FAISS index.")
def chunk_text(text, chunk_size=500):
"""Split text into smaller chunks"""
words = text.split()
return [" ".join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)]
def get_blog_posts():
"""Fetch published blog posts from WordPress database."""
try:
conn = mariadb.connect(
user=DB_USER,
password=DB_PASSWORD,
host=DB_HOST,
database=DB_NAME
)
cursor = conn.cursor()
cursor.execute("""
SELECT ID, post_title, post_content
FROM wp_posts
WHERE post_status='publish' AND post_type='post'
""")
posts = cursor.fetchall()
conn.close()
return posts
except mariadb.Error as e:
print(f"❌ Database error: {e}")
return []
def index_blog_posts():
"""Index only new blog posts in FAISS"""
blog_posts = get_blog_posts()
if not blog_posts:
print("❌ No blog posts found. Check database connection.")
return
vectors = []
new_metadata = {}
current_index = len(metadata)
print(f"📝 Found {len(blog_posts)} blog posts to check for indexing.")
for post_id, title, content in blog_posts:
if any(str(idx) for idx in metadata if metadata[idx]["post_id"] == post_id):
print(f"🔄 Skipping already indexed post: {title} (ID: {post_id})")
continue
chunks = chunk_text(content)
for chunk in chunks:
embedding = model.encode(chunk, normalize_embeddings=True) # Normalize embeddings
vectors.append(embedding)
new_metadata[current_index] = {
"post_id": post_id,
"title": title,
"chunk_text": chunk
}
current_index += 1
if vectors:
faiss_vectors = np.array(vectors, dtype=np.float32)
index.add(faiss_vectors)
metadata.update(new_metadata)
faiss.write_index(index, index_file)
with open(metadata_file, "w") as f:
json.dump(metadata, f, indent=4)
print(f"✅ Indexed {len(new_metadata)} new chunks.")
else:
print("✅ No new posts to index.")
if __name__ == "__main__":
index_blog_posts()
print("✅ Indexing completed.")
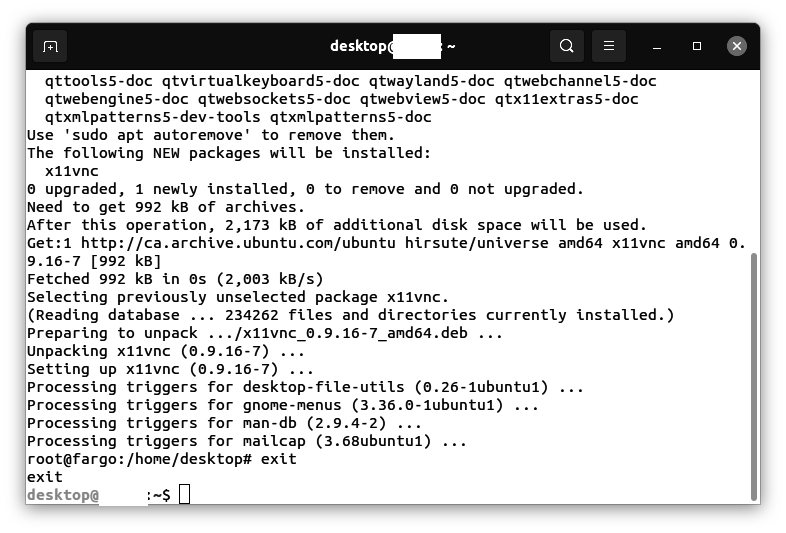
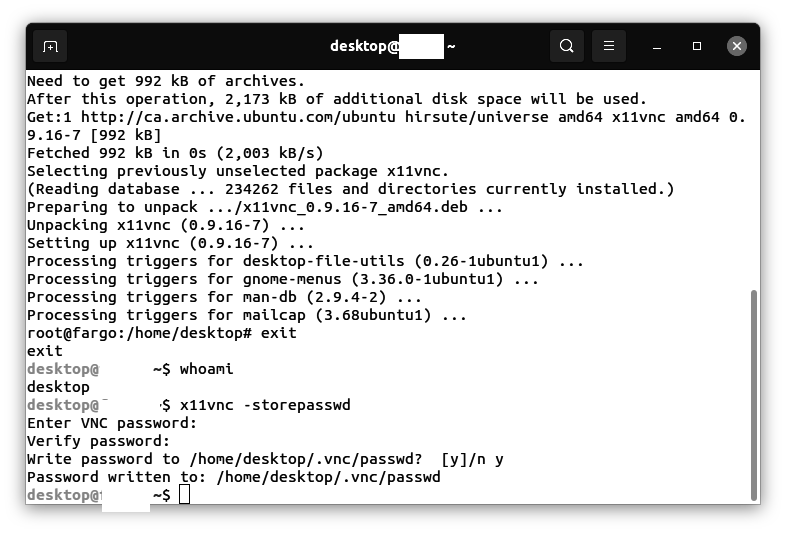
Save and exit the file.
Creating the FAISS retrieval API
Enter the following command:
nano faiss_search.py
Use the nano editor to add text to the file:
import os
import faiss
import numpy as np
import json
from sentence_transformers import SentenceTransformer # ✅ Ensure this is imported
# MIT license Gordon Buchan 2025
# see https://opensource.org/license/mit
# some of the code was generated with the assistance of AI tools.
# ✅ Load the same embedding model used in `rag_api_wrapper.py`
model = SentenceTransformer("all-MiniLM-L6-v2")
# ✅ Load FAISS index and metadata
index_file = "faiss_index.bin"
metadata_file = "faiss_metadata.json"
embedding_dim = 384
if os.path.exists(index_file):
index = faiss.read_index(index_file)
with open(metadata_file, "r") as f:
metadata = json.load(f)
else:
index = faiss.IndexFlatL2(embedding_dim)
metadata = {}
def search_faiss(query_text, top_k=10):
"""Search FAISS index and retrieve relevant metadata"""
query_embedding = model.encode(query_text).reshape(1, -1) # ✅ Ensure `model` is used correctly
_, indices = index.search(query_embedding, top_k)
results = []
for idx in indices[0]:
if str(idx) in metadata: # ✅ Convert index to string to match JSON keys
results.append(metadata[str(idx)])
return results
Save and exit the file.
Creating the RAG API wrapper
Enter the following command:
nano rag_api_wrapper.py
Use the nano editor to add the following text:
from fastapi import FastAPI, HTTPException
import requests
import os
import json
import faiss
import numpy as np
from dotenv import load_dotenv
from sentence_transformers import SentenceTransformer
# MIT license Gordon Buchan 2025
# see https://opensource.org/license/mit
# some of the code was generated with the assistance of AI tools.
# Load environment variables
load_dotenv(dotenv_path="./.env")
EXTERNAL_LLM_API = os.getenv('EXTERNAL_LLM_API')
EXTERNAL_LLM_API_KEY = os.getenv('EXTERNAL_LLM_API_KEY')
BLOG_URL_BASE = os.getenv('BLOG_URL_BASE')
# Load FAISS index and metadata
embedding_dim = 384
index_file = "faiss_index.bin"
metadata_file = "faiss_metadata.json"
if os.path.exists(index_file):
index = faiss.read_index(index_file)
with open(metadata_file, "r") as f:
metadata = json.load(f)
metadata = {int(k): v for k, v in metadata.items()} # Ensure integer keys
print(f"📂 Loaded FAISS index with {index.ntotal} embeddings.")
else:
index = faiss.IndexHNSWFlat(embedding_dim, 32)
metadata = {}
print("❌ No FAISS index found.")
# Load embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
app = FastAPI()
def search_faiss(query_text, top_k=3):
"""Retrieve top K relevant chunks from FAISS index"""
if index.ntotal == 0:
return []
query_embedding = model.encode(query_text, normalize_embeddings=True).reshape(1, -1)
distances, indices = index.search(query_embedding, top_k)
results = []
for idx in indices[0]:
if idx in metadata:
post_id = metadata[idx]["post_id"]
title = metadata[idx]["title"]
chunk_text = metadata[idx]["chunk_text"]
post_url = f"{BLOG_URL_BASE}/?p={post_id}"
# Limit chunk text to 300 characters for cleaner display
short_chunk = chunk_text[:300] + "..." if len(chunk_text) > 300 else chunk_text
results.append(f"📌 {title}: {short_chunk} (Read more: {post_url})")
return results[:3] # Limit to max 3 sources
@app.post("/v1/chat/completions")
def chat_completions(request: dict):
if "messages" not in request:
raise HTTPException(status_code=400, detail="No messages provided.")
user_query = request["messages"][-1]["content"]
# Retrieve relevant blog context
context_snippets = search_faiss(user_query)
context_text = "\n".join(context_snippets) if context_snippets else "No relevant sources found."
# Send query with context to LLM API
payload = {
"model": "llama-8b-chat",
"messages": [
{"role": "system", "content": "Use the following blog snippets to provide a detailed response."},
{"role": "user", "content": f"{user_query}\n\nContext:\n{context_text}"}
]
}
headers = {"Authorization": f"Bearer {EXTERNAL_LLM_API_KEY}"}
response = requests.post(EXTERNAL_LLM_API, json=payload, headers=headers)
if response.status_code != 200:
raise HTTPException(status_code=500, detail="External LLM API request failed.")
llm_response = response.json()
response_text = llm_response["choices"][0]["message"]["content"]
return {
"id": llm_response.get("id", "generated_id"),
"object": "chat.completion",
"created": llm_response.get("created", 1700000000),
"model": llm_response.get("model", "llama-8b-chat"),
"choices": [
{
"message": {
"role": "assistant",
"content": f"{response_text}\n\n📚 Sources:\n{context_text}"
}
}
],
"usage": llm_response.get("usage", {"prompt_tokens": 0, "completion_tokens": 0, "total_tokens": 0})
}
Save and exit the file.
Running the rag_faiss.py file manually to create the FAISS vector database
Enter the following command:
python3 rag_faiss.py
Starting the RAG API wrapper manually to test the system
curl -X POST http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"messages": [{"role": "user", "content": "How do I use an external LLM API?"}]}'
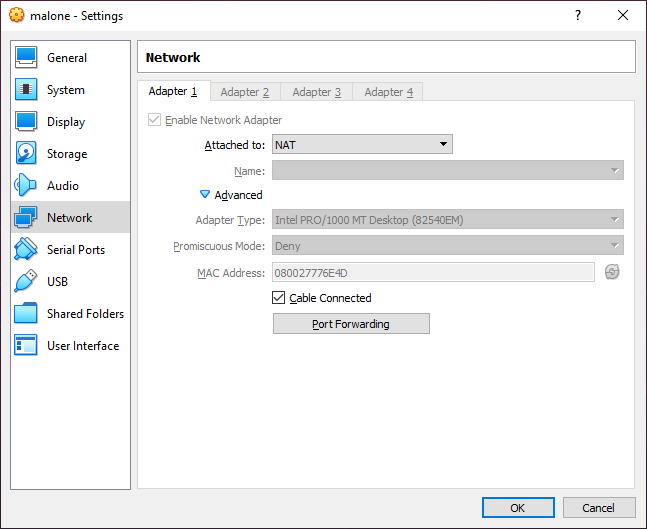
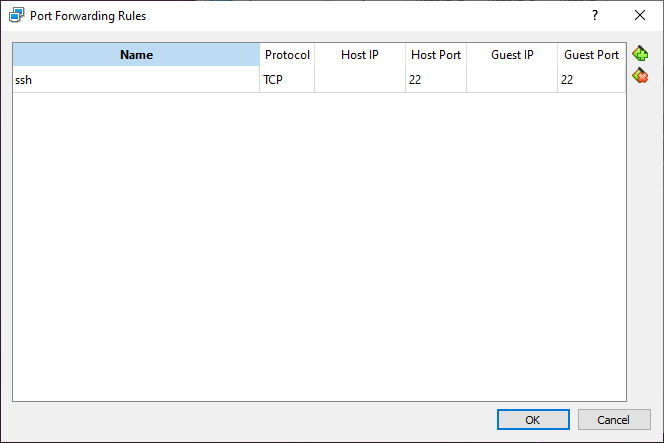
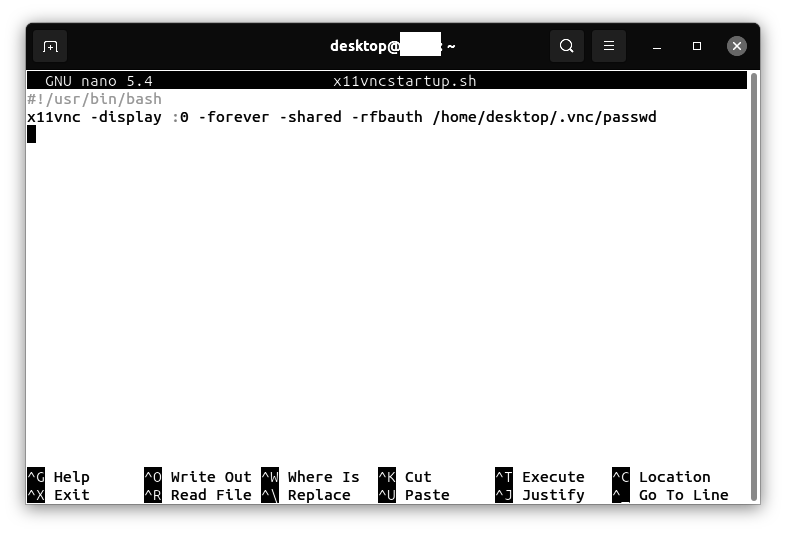
Adding the shortcode widget to add the chatbot to the WordPress sidebar
Go to the section “Appearance” | “Widgets.”
Select the sidebar area. Click on the “+” symbol. Search for “shortcode,” click on the short code icon.
In the text box marked “Write shortcode here…” Enter the shortcode:
[rag_chatbot]
Click on Update.
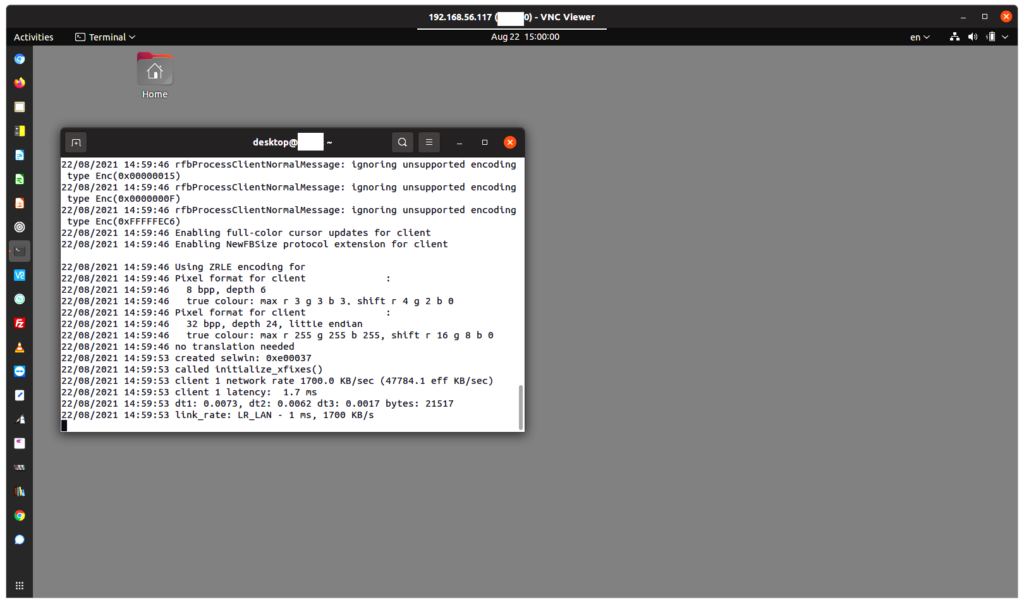
Checking that the chatbot has been added to the sidebar of the blog
Go to the main page of the blog. Look to ensure that the short code element has been added to the blog’s sidebar. Test the chatbot (suggested query: “Tell me about LLMs.”):
Open-WebUI, a web chat server for LLMs, is not compatible with some LLM APIs that support the chat completions API, and use a message array. Although there are other tools available, I wanted to use Open-WebUI. I resolved this by creating a proxy server that acts as a translation layer between the Open-WebUI chat server and an LLM API server that supports the chat completions API and uses a message array.
I wanted to use Open-WebUI as my chat server, but Open-WebUI is not compatible with the API of my remotely hosted LLM API inference service
Open-WebUI was designed to be compatible with Ollama, a tool that hosts an LLM locally and exposes an API. However, instead of using a locally-hosted LLM, I would like to use an LLM inference API service provided by lemonfox.ai, which emulates the OpenAI API including the chat completions API, and uses a message array.
Considering the value of a remote LLM inference API server over a locally-hosted solution
In this blog post, we create a proxy server that enables the Open-WebUI chat server to connect to an OpenAI-compatible API. Although it is an interesting technical exercise to self-host, as a business case it does not make sense for long-term production. Certain kinds of LLM inference workloads can be handled by a CPU-only system, using a tool like Ollama, but the performance is not sufficient for real-time interaction. Dedicating GPU-enabled hardware is a significant expense, whether it be the acquisition of dedicated GPU hardware such as an A30, H100, RTX 4090, or RTX 5090 card. Renting or leasing this hardware is even more expensive. We seem to be heading into an era in which LLM inference itself is software as a service (SaaS), unless there are specific reasons why inference data cannot be shared with a public cloud, such as a legal or medical application.
Using a proxy server as a translation layer between incompatible APIs
There are many chat user interfaces available, but Open-WebUI has been easier to deploy and for the moment is my preference. The need for proxy servers to translate between LLM API servers that have slightly different protocols will likely be with us for some time, until LLM APIs have matured and become more compatible.
Using a remotely-hosted LLM inference API with a toolchain of applications and proxies
At this time in 2025, most LLM inference APIs emulate the OpenAI protocol, with support for the chat completions API and the use of a message array. In this exercise, we will be connecting the Open-WebUI chat server to an OpenAI compatible LLM API. In the future, we may see more abstracted toolchains, for example, a retrieval augmented generation (RAG) server offering an API that encapsulates the local RAG functionality and enhanced by the remote LLM inference API, to which a chat server will connect. In this case, the chat server will be Open-WebUI, but in other applications it could be a web chat user interface embedded in a website.
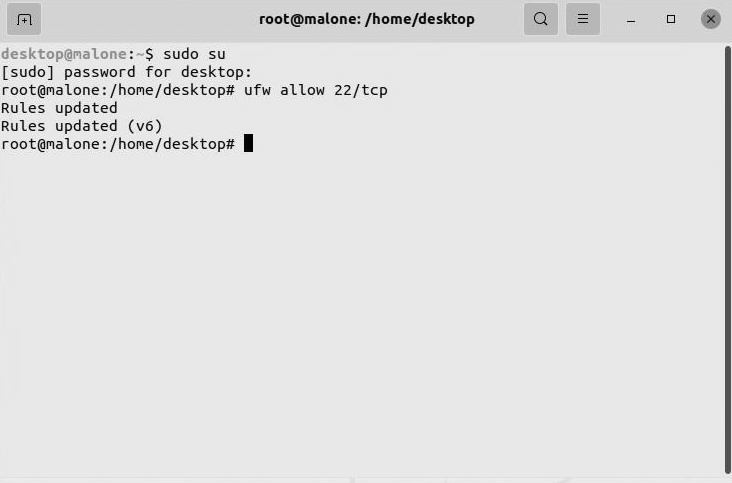
Escalating to the root user with sudo
Enter the following command:
sudo su
Creating a virtual environment and installing dependencies
Enter the following commands:
cd ~
mkdir proxy_workdir
cd proxy_workdir
python3 -m venv proxy_env
source proxy_env/bin/activate
pip install fastapi uvicorn httpx python-dotenv
Creating the proxy.py file
Enter the following command:
nano proxy.py
Use the nano editor to add the following text:
# MIT license Gordon Buchan 2025
# see https://opensource.org/license/mit
# Some of this code was generated with the assistance of AI tools.
from fastapi import FastAPI, Request
import httpx
import logging
import json
import time
app = FastAPI()
# Enable logging for debugging
logging.basicConfig(level=logging.DEBUG)
# LemonFox API details
LEMONFOX_API_URL = "https://api.lemonfox.ai/v1/chat/completions"
API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
@app.get("/api/openai/v1/models")
async def get_models():
return {
"object": "list",
"data": [
{
"id": "mixtral-chat",
"object": "model",
"owned_by": "lemonfox"
}
]
}
async def make_request_with_retry(payload):
"""Send request to LemonFox API with one retry in case of failure."""
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
for attempt in range(2): # Try twice before failing
async with httpx.AsyncClient() as client:
try:
response = await client.post(LEMONFOX_API_URL, json=payload, headers=headers)
response_json = response.json()
# If response is valid, return it
if "choices" in response_json and response_json["choices"]:
return response_json
logging.warning(f"❌ Empty response from LemonFox on attempt {attempt + 1}: {response_json}")
except httpx.HTTPStatusError as e:
logging.error(f"❌ LemonFox API HTTP error: {e}")
except json.JSONDecodeError:
logging.error(f"❌ LemonFox returned an invalid JSON response: {response.text}")
# Wait 1 second before retrying
time.sleep(1)
# If we get here, both attempts failed—return a default response
logging.error("❌ LemonFox API failed twice. Returning a fallback response.")
return {
"id": "fallback-response",
"object": "chat.completion",
"created": int(time.time()),
"model": "unknown",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "I'm sorry, but I couldn't generate a response. Try again."
},
"finish_reason": "stop"
}
],
"usage": {"prompt_tokens": 0, "completion_tokens": 0, "total_tokens": 0}
}
@app.post("/api/openai/v1/chat/completions")
async def proxy_chat_completion(request: Request):
"""Ensure Open WebUI's request is converted and always return a valid response."""
try:
payload = await request.json()
logging.debug("🟢 Open WebUI Request: %s", json.dumps(payload, indent=2))
# Convert `prompt` into OpenAI's `messages[]` format
if "prompt" in payload:
payload["messages"] = [{"role": "user", "content": payload["prompt"]}]
del payload["prompt"]
elif "messages" not in payload or not isinstance(payload["messages"], list):
logging.error("❌ Open WebUI sent an invalid request!")
return {"error": "Invalid request format. Expected `messages[]` or `prompt`."}
# Force disable streaming
payload["stream"] = False
# Set max tokens to a high value to avoid truncation
payload.setdefault("max_tokens", 4096)
# Call LemonFox with retry logic
response_json = await make_request_with_retry(payload)
# Ensure response follows OpenAI format
if "choices" not in response_json or not response_json["choices"]:
logging.error("❌ LemonFox returned an empty `choices[]` array after retry!")
response_json["choices"] = [
{
"index": 0,
"message": {
"role": "assistant",
"content": "I'm sorry, but I didn't receive a valid response."
},
"finish_reason": "stop"
}
]
logging.debug("🟢 Final Response Sent to Open WebUI: %s", json.dumps(response_json, indent=2))
return response_json
except Exception as e:
logging.error("❌ Unexpected Error in Proxy: %s", str(e))
return {"error": str(e)}
Save and exit the file.
Running the proxy server manually
Enter the following command:
uvicorn proxy:app --host 0.0.0.0 --port 8000
Configuring Open-WebUI
Go to Open-WebUI Settings | Connections
Set API Base URL to:
http://localhost:8000/api/openai/v1
Ensure that model name matches:
mixtral-chat
Testing Open-WebUI with a simple message
Enter some text in the chat window and see if you get a response from the LLM.
Creating the systemd service
Enter the following command:
nano /etc/systemd/system/open-webui-proxy.service
Use the nano editor to add the following text:
[Unit]
Description=open-webui Proxy for Open WebUI and LLM API
After=network.target
[Service]
Type=simple
WorkingDirectory=/root/proxy_workdir # Change to your script's location
ExecStart=/usr/bin/env bash -c "source /root/proxy_workdir/proxy_env/bin/activate && uvicorn proxy:app --host 0.0.0.0 --port 8000"
Restart=always
RestartSec=5
User=root
Group=root
StandardOutput=journal
StandardError=journal
[Install]
WantedBy=multi-user.target
As of early 2025, large language models (LLMs) are primarily accessed through web interfaces offered by companies like OpenAI, Anthropic (Perplexity/Claude), and Google (Gemini). Alongside these proprietary offerings, a “second tier” of open-source LLM models has emerged, including Meta’s LLaMA 3.1, Mistral, DeepSeek, and others. These open-source models are becoming increasingly viable for self-hosting, offering significant advantages in data sovereignty, confidentiality, and cost savings. For many use cases, they are roughly on par with proprietary models, making them an appealing alternative.
While web interfaces are the most visible way to interact with LLMs, they are largely loss leaders, designed to promote application programming interface (API) services. APIs are the backbone of the LLM ecosystem, enabling developers to integrate LLM capabilities into their own software. Through APIs, businesses can pass data and instructions to an LLM and retrieve outputs tailored to their needs. These APIs are central to the value proposition of LLMs, powering applications like retrieval-augmented generation (RAG) workflows for the scanning of document collections, automated form processing, and natural language interfaces for structured databases.
The growing market for LLM APIs
OpenAI was the first major player to offer an API for its LLMs, and its design has become a de facto standard, with many other LLM providers emulating its structure. This compatibility has paved the way for a competitive LLM inference hosting market. Applications leveraging APIs can often switch between providers with minimal effort, simply by changing the host address and API key. This interoperability is fostering a dynamic market for LLM inferencing, where cost, performance, and data privacy are key differentiators.
Example of an LLM API call
Here’s an example of a basic API call using curl. This same structure is supported by most LLM APIs:
curl https://api.lemonfox.ai/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "mixtral-chat",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Why is the sky blue?" }
]
}'
This straightforward interface makes it easy for developers to integrate LLM capabilities into their applications, whether for natural language understanding, data extraction, or other advanced AI tasks.
Note: you may notice differences between this API call and the API calls we used with Ollama and Open-WebUI in previous blog posts. Ollama and Open-WebUI use a simplified protocol using a prompt field. The example above uses a messages array, compatible with the chat completions API, used by OpenAI and implemented by third parties such as lemonfox.ai
A historical parallel: LLM hosting and the web hosting market of the 2000s
The current trajectory of LLM inference hosting bears striking similarities to the early days of web hosting in the late 1990s and early 2000s. Back then, the advent of open-source technologies like Linux, Apache, MySQL, and PHP enabled hobbyists and businesses to build industrial-grade web servers on consumer hardware. While some opted to host websites themselves, most turned to professional web hosting providers, creating a competitive market that eventually drove down prices and established commoditized hosting as the norm.
Similarly, the LLM inference hosting market is evolving into a spectrum of options:
Self-hosting: Organizations can invest in high-performance hardware like NVIDIA’s H100 GPUs (priced at around US$30,000) or more modest setups using GPUs like the RTX 4090 or RTX 5090 (priced at around US$5,000). This option offers full control but requires significant upfront investment and technical expertise.
Leased GPU services: Cloud providers offer GPU resources on an hourly basis, making it possible to run LLMs without committing to physical hardware. For example, renting an H100 GPU typically costs around US$3 per hour.
Hosted inference services: Many providers offer LLM inference as a service, where customers pay per transaction or token. This model eliminates the need for infrastructure management, appealing to businesses that prioritize simplicity.
The economics of LLM hosting
The emergence of open-source models and interoperable APIs is driving fierce competition in the LLM hosting market. This competition has already led to dramatic price differences between providers. For example:
lemonfox.ai Mistral 7B: US$5 per 10 million tokens (using open-source models)
These disparities highlight the potential cost savings of opting for open-source models hosted by third-party providers or self-hosting solutions.
Renting GPUs vs. buying inference services
For businesses and developers, choosing between renting GPU time, self-hosting, or using inference services depends on several factors:
Scalability: Hosted inference services are ideal for unpredictable or spiky workloads, as they scale effortlessly.
Cost efficiency: For steady, high-volume workloads, self-hosting may be more economical in the long run.
Data control: Organizations with strict confidentiality requirements may prefer self-hosting to ensure data never leaves their infrastructure.
Open source software is free as in freedom, and free as in free beer. Although there are significant hardware costs for GPU capability, in general an enterprise can self-host AI without incurring software licensing fees.
Price competition from vendors using open source solutions no doubt has the effect of constraining the pricing power of closed source vendors.
For example, a small startup building a chatbot might initially use an inference provider like lemonfox.ai to minimize costs and complexity. As their user base grows, they might transition to leased GPU services or invest in dedicated hardware to optimize expenses.
A law firm or medical practice may begin with an air-gapped cloud instance with non-disclosure (NDA) and data protection (DPA) agreements. At some point, the business case may justify taking the service in-house with a self-hosted inference server with GPU hardware.
Conclusion: the road ahead for LLM inference hosting
As LLMs continue to gain traction, the LLM inference hosting market will likely follow the trajectory of web hosting two decades ago—moving toward commoditization and low-margin competition. Businesses and individuals will increasingly weigh the trade-offs between cost, control, and convenience when deciding how to deploy LLM capabilities. The availability of open-source models and interoperable APIs ensures that options will continue to expand, empowering developers to choose the solution that best meets their needs.
In this post, we create a Python script that connects to a Gmail inbox, extracts the text of the subject and body of each message, submits that text with a prompt to a large language model (LLM), then if conditions are met that match the prompt, escalates the message to the attention of an operator, based on a prompt.
Create a new app password. Take note of the password, it will not be visible again.
Note: Google adds spaces to the app password for readability. You should remove the spaces from the app password and use that value.
Escalating to the root user
In this procedure we run as the root user. Enter the following command:
sudo su
Adding utilities to the operating system
Enter the following command:
apt install python3-venv python3-pip sqlite3
Creating a virtual environment and installing required packages with pip
Enter the following commands:
cd ~
mkdir doicareworkdir
cd doicareworkdir
python3 -m venv doicare_env
source doicare_env/bin/activate
pip install requests imaplib2
Creating the configuration file (config.json)
Enter the following command:
nano config.json
Use the nano editor to add the following text:
{
"gmail_user": "xxxxxxxxxxxx@xxxxx.xxx",
"gmail_app_password": "xxxxxxxxxxxxxxxx",
"api_base_url": "http://xxx.xxx.xxx.xxx:8085",
"openai_api_key": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"database": "doicare.db",
"scanasof": "18-Jan-2025",
"alert_recipients": [
"xxxxx@xxxxx.com"
],
"smtp_server": "smtp.gmail.com",
"smtp_port": 587,
"smtp_user": "xxxxxx@xxxxx.xxxxx",
"smtp_password": "xxxxxxxxxxxxxxxx",
"analysis_prompt": "Analyze the email below. If it needs escalation (urgent, sender upset, or critical issue), return 'Escalation Reason:' followed by one short sentence explaining why. If no escalation is needed, return exactly 'DOESNOTAPPLY'. Always provide either 'DOESNOTAPPLY' or a reason.",
"model": "mistral"
}
Save and exit the file.
Creating a Python script called doicare that connects to a Gmail inbox, submits messages to an LLM, and escalates messages based on a prompt (Ollama version)
Enter the following command:
nano doicare_gmail.py
import imaplib
import email
import sqlite3
import requests
import smtplib
import json
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import decode_header, make_header
# MIT license 2025 Gordon Buchan
# see https://opensource.org/licenses/MIT
# Some of this code was generated with the assistance of AI tools.
# --------------------------------------------------------------------
# 1. LOAD CONFIG
# --------------------------------------------------------------------
with open("config.json", "r") as cfg:
config = json.load(cfg)
GMAIL_USER = config["gmail_user"]
GMAIL_APP_PASSWORD = config["gmail_app_password"]
API_BASE_URL = config["api_base_url"]
OPENAI_API_KEY = config["openai_api_key"]
DATABASE = config["database"]
SCAN_ASOF = config["scanasof"]
ALERT_RECIPIENTS = config.get("alert_recipients", [])
SMTP_SERVER = config["smtp_server"]
SMTP_PORT = config["smtp_port"]
SMTP_USER = config["smtp_user"]
SMTP_PASSWORD = config["smtp_password"]
ANALYSIS_PROMPT = config["analysis_prompt"]
MODEL = config["model"]
# --------------------------------------------------------------------
# 2. DATABASE SETUP
# --------------------------------------------------------------------
def setup_database():
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS escalations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
email_date TEXT,
from_address TEXT,
to_address TEXT,
cc_address TEXT,
subject TEXT,
body TEXT,
reason TEXT,
created_at TEXT
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS scan_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
last_scanned_uid INTEGER
)
""")
conn.commit()
conn.close()
def get_last_scanned_uid():
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT last_scanned_uid FROM scan_info ORDER BY id DESC LIMIT 1")
row = cur.fetchone()
conn.close()
return row[0] if (row and row[0]) else 0
def update_last_scanned_uid(uid_val):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("INSERT INTO scan_info (last_scanned_uid) VALUES (?)", (uid_val,))
conn.commit()
conn.close()
def is_already_processed(uid_val):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT 1 FROM scan_info WHERE last_scanned_uid = ?", (uid_val,))
row = cur.fetchone()
conn.close()
return bool(row)
# --------------------------------------------------------------------
# 3. ANALYSIS & ALERTING
# --------------------------------------------------------------------
def analyze_with_openai(subject, body):
prompt = f"{ANALYSIS_PROMPT}\n\nSubject: {subject}\nBody: {body}"
url = f"{API_BASE_URL}/v1/completions"
headers = {"Content-Type": "application/json"}
if OPENAI_API_KEY:
headers["Authorization"] = f"Bearer {OPENAI_API_KEY}"
payload = {
"model": MODEL,
"prompt": prompt,
"max_tokens": 300,
"temperature": 0.7
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=60)
data = response.json()
if "error" in data:
print(f"[DEBUG] API Error: {data['error']['message']}")
return "DOESNOTAPPLY"
if "choices" in data and data["choices"]:
raw_text = data["choices"][0]["text"].strip()
return raw_text
return "DOESNOTAPPLY"
except Exception as e:
print(f"[DEBUG] Exception during API call: {e}")
return "DOESNOTAPPLY"
def send_alerts(reason, email_date, from_addr, to_addr, cc_addr, subject, body):
for recipient in ALERT_RECIPIENTS:
msg = MIMEMultipart()
msg["From"] = SMTP_USER
msg["To"] = recipient
msg["Subject"] = "Escalation Alert"
alert_text = f"""
Escalation Triggered
Date: {email_date}
From: {from_addr}
To: {to_addr}
CC: {cc_addr}
Subject: {subject}
Body: {body}
Reason: {reason}
"""
msg.attach(MIMEText(alert_text, "plain"))
try:
with smtplib.SMTP(SMTP_SERVER, SMTP_PORT) as server:
server.starttls()
server.login(SMTP_USER, SMTP_PASSWORD)
server.sendmail(SMTP_USER, recipient, msg.as_string())
print(f"Alert sent to {recipient}")
except Exception as ex:
print(f"Failed to send alert to {recipient}: {ex}")
def save_escalation(email_date, from_addr, to_addr, cc_addr, subject, body, reason):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
INSERT INTO escalations (
email_date, from_address, to_address, cc_address,
subject, body, reason, created_at
) VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
email_date, from_addr, to_addr, cc_addr,
subject, body, reason, datetime.now().isoformat()
))
conn.commit()
conn.close()
# --------------------------------------------------------------------
# 4. MAIN LOGIC
# --------------------------------------------------------------------
def process_message(raw_email, uid_val):
parsed_msg = email.message_from_bytes(raw_email)
date_str = parsed_msg.get("Date", "")
from_addr = parsed_msg.get("From", "")
to_addr = parsed_msg.get("To", "")
cc_addr = parsed_msg.get("Cc", "")
subject_header = parsed_msg.get("Subject", "")
subject_decoded = str(make_header(decode_header(subject_header)))
body_text = ""
if parsed_msg.is_multipart():
for part in parsed_msg.walk():
ctype = part.get_content_type()
disposition = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in disposition:
charset = part.get_content_charset() or "utf-8"
body_text += part.get_payload(decode=True).decode(charset, errors="replace")
else:
charset = parsed_msg.get_content_charset() or "utf-8"
body_text = parsed_msg.get_payload(decode=True).decode(charset, errors="replace")
reason = analyze_with_openai(subject_decoded, body_text)
if "DOESNOTAPPLY" in reason:
print(f"[UID {uid_val}] No escalation: {reason}")
return
print(f"[UID {uid_val}] Escalation triggered: {subject_decoded[:50]}")
save_escalation(date_str, from_addr, to_addr, cc_addr, subject_decoded, body_text, reason)
send_alerts(reason, date_str, from_addr, to_addr, cc_addr, subject_decoded, body_text)
def main():
setup_database()
last_uid = get_last_scanned_uid()
print(f"[DEBUG] Retrieved last UID: {last_uid}")
try:
mail = imaplib.IMAP4_SSL("imap.gmail.com")
mail.login(GMAIL_USER, GMAIL_APP_PASSWORD)
print("IMAP login successful.")
except Exception as e:
print(f"Error logging into Gmail: {e}")
return
mail.select("INBOX")
if last_uid == 0:
print(f"[DEBUG] First run: scanning since date {SCAN_ASOF}")
r1, d1 = mail.search(None, f'(SINCE {SCAN_ASOF})')
else:
print(f"[DEBUG] Subsequent run: scanning for UIDs > {last_uid}")
r1, d1 = mail.uid('SEARCH', None, f'UID {last_uid + 1}:*')
if r1 != "OK":
print("[DEBUG] Search failed.")
mail.logout()
return
seq_nums = d1[0].split()
print(f"[DEBUG] Found {len(seq_nums)} messages to process: {seq_nums}")
if not seq_nums:
print("[DEBUG] No messages to process.")
mail.logout()
return
highest_uid_seen = last_uid
for seq_num in seq_nums:
if is_already_processed(seq_num.decode()):
print(f"[DEBUG] UID {seq_num.decode()} already processed, skipping.")
continue
print(f"[DEBUG] Processing sequence number: {seq_num}")
r2, d2 = mail.uid('FETCH', seq_num.decode(), '(RFC822)')
if r2 != "OK" or not d2 or len(d2) < 1 or not d2[0]:
print(f"[DEBUG] Failed to fetch message for UID {seq_num.decode()}")
continue
print(f"[DEBUG] Successfully fetched message for UID {seq_num.decode()}")
raw_email = d2[0][1]
try:
process_message(raw_email, int(seq_num.decode()))
mail.uid('STORE', seq_num.decode(), '+FLAGS', '\\Seen')
if int(seq_num.decode()) > highest_uid_seen:
highest_uid_seen = int(seq_num.decode())
except Exception as e:
print(f"[DEBUG] Error processing message UID {seq_num.decode()}: {e}")
if highest_uid_seen > last_uid:
print(f"[DEBUG] Updating last scanned UID to {highest_uid_seen}")
update_last_scanned_uid(highest_uid_seen)
mail.logout()
if __name__ == "__main__":
main()
Save and exit the file.
Creating a Python script called doicare that connects to a Gmail inbox, submits messages to an LLM, and escalates messages based on a prompt (OpenAI-compatible version)
Enter the following command:
nano doicare_gmail.py
import imaplib
import email
import sqlite3
import requests
import smtplib
import json
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import decode_header, make_header
# MIT license 2025 Gordon Buchan
# see https://opensource.org/licenses/MIT
# Some of this code was generated with the assistance of AI tools.
# --------------------------------------------------------------------
# 1. LOAD CONFIG
# --------------------------------------------------------------------
with open("config.json", "r") as cfg:
config = json.load(cfg)
GMAIL_USER = config["gmail_user"]
GMAIL_APP_PASSWORD = config["gmail_app_password"]
API_BASE_URL = config["api_base_url"]
OPENAI_API_KEY = config["openai_api_key"]
DATABASE = config["database"]
SCAN_ASOF = config["scanasof"]
ALERT_RECIPIENTS = config.get("alert_recipients", [])
SMTP_SERVER = config["smtp_server"]
SMTP_PORT = config["smtp_port"]
SMTP_USER = config["smtp_user"]
SMTP_PASSWORD = config["smtp_password"]
ANALYSIS_PROMPT = config["analysis_prompt"]
MODEL = config["model"]
# --------------------------------------------------------------------
# 2. DATABASE SETUP
# --------------------------------------------------------------------
def setup_database():
""" Ensure the database and necessary tables exist. """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
print("[DEBUG] Ensuring database tables exist...")
cur.execute("""
CREATE TABLE IF NOT EXISTS escalations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
email_date TEXT,
from_address TEXT,
to_address TEXT,
cc_address TEXT,
subject TEXT,
body TEXT,
reason TEXT,
created_at TEXT
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS scan_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
last_scanned_uid INTEGER UNIQUE
)
""")
# Ensure at least one row exists in scan_info
cur.execute("SELECT COUNT(*) FROM scan_info")
if cur.fetchone()[0] == 0:
cur.execute("INSERT INTO scan_info (last_scanned_uid) VALUES (0)")
conn.commit()
conn.close()
print("[DEBUG] Database setup complete.")
def get_last_scanned_uid():
""" Retrieve the last scanned UID from the database """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT last_scanned_uid FROM scan_info ORDER BY id DESC LIMIT 1")
row = cur.fetchone()
conn.close()
return int(row[0]) if (row and row[0]) else 0
def update_last_scanned_uid(uid_val):
""" Update the last scanned UID in the database """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
INSERT INTO scan_info (id, last_scanned_uid)
VALUES (1, ?)
ON CONFLICT(id) DO UPDATE SET last_scanned_uid = excluded.last_scanned_uid
""", (uid_val,))
conn.commit()
conn.close()
# --------------------------------------------------------------------
# 3. ANALYSIS & ALERTING
# --------------------------------------------------------------------
def analyze_with_openai(subject, body):
""" Send email content to OpenAI API for analysis """
prompt = f"{ANALYSIS_PROMPT}\n\nSubject: {subject}\nBody: {body}"
url = f"{API_BASE_URL}/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {OPENAI_API_KEY}" if OPENAI_API_KEY else "",
}
payload = {
"model": MODEL,
"messages": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": prompt}
],
"max_tokens": 300,
"temperature": 0.7
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=60)
data = response.json()
if "error" in data:
print(f"[DEBUG] API Error: {data['error']['message']}")
return "DOESNOTAPPLY"
if "choices" in data and data["choices"]:
return data["choices"][0]["message"]["content"].strip()
return "DOESNOTAPPLY"
except Exception as e:
print(f"[DEBUG] Exception during API call: {e}")
return "DOESNOTAPPLY"
# --------------------------------------------------------------------
# 4. MAIN LOGIC
# --------------------------------------------------------------------
def process_message(raw_email, uid_val):
""" Process a single email message """
parsed_msg = email.message_from_bytes(raw_email)
date_str = parsed_msg.get("Date", "")
from_addr = parsed_msg.get("From", "")
to_addr = parsed_msg.get("To", "")
cc_addr = parsed_msg.get("Cc", "")
subject_header = parsed_msg.get("Subject", "")
subject_decoded = str(make_header(decode_header(subject_header)))
body_text = ""
if parsed_msg.is_multipart():
for part in parsed_msg.walk():
ctype = part.get_content_type()
disposition = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in disposition:
charset = part.get_content_charset() or "utf-8"
body_text += part.get_payload(decode=True).decode(charset, errors="replace")
else:
charset = parsed_msg.get_content_charset() or "utf-8"
body_text = parsed_msg.get_payload(decode=True).decode(charset, errors="replace")
reason = analyze_with_openai(subject_decoded, body_text)
if "DOESNOTAPPLY" in reason:
print(f"[UID {uid_val}] No escalation: {reason}")
return
print(f"[UID {uid_val}] Escalation triggered: {subject_decoded[:50]}")
update_last_scanned_uid(uid_val)
def main():
""" Main function to fetch and process emails """
setup_database()
last_uid = get_last_scanned_uid()
print(f"[DEBUG] Retrieved last UID: {last_uid}")
try:
mail = imaplib.IMAP4_SSL("imap.gmail.com")
mail.login(GMAIL_USER, GMAIL_APP_PASSWORD)
print("IMAP login successful.")
except Exception as e:
print(f"Error logging into Gmail: {e}")
return
mail.select("INBOX")
search_query = f'UID {last_uid + 1}:*' if last_uid > 0 else f'SINCE {SCAN_ASOF}'
print(f"[DEBUG] Running IMAP search: {search_query}")
r1, d1 = mail.uid('SEARCH', None, search_query)
if r1 != "OK":
print("[DEBUG] Search failed.")
mail.logout()
return
seq_nums = d1[0].split()
seq_nums = [seq.decode() for seq in seq_nums]
print(f"[DEBUG] Found {len(seq_nums)} new messages: {seq_nums}")
if not seq_nums:
print("[DEBUG] No new messages found, exiting.")
mail.logout()
return
highest_uid_seen = last_uid
for seq_num in seq_nums:
numeric_uid = int(seq_num)
if numeric_uid <= last_uid:
print(f"[DEBUG] UID {numeric_uid} already processed, skipping.")
continue
print(f"[DEBUG] Processing UID: {numeric_uid}")
r2, d2 = mail.uid('FETCH', seq_num, '(RFC822)')
if r2 != "OK" or not d2 or len(d2) < 1 or not d2[0]:
print(f"[DEBUG] Failed to fetch message for UID {numeric_uid}")
continue
raw_email = d2[0][1]
process_message(raw_email, numeric_uid)
highest_uid_seen = max(highest_uid_seen, numeric_uid)
if highest_uid_seen > last_uid:
print(f"[DEBUG] Updating last scanned UID to {highest_uid_seen}")
update_last_scanned_uid(highest_uid_seen)
mail.logout()
if __name__ == "__main__":
main()
Save and exit the file.
Running the doicare_gmail.py script
Enter the following command:
python3 doicare_gmail.py
Sample output
(doicare_env) root@xxxxx:/home/desktop/doicareworkingdir# python3 doicare_gmail.py
[DEBUG] Retrieved last UID: 0
IMAP login successful.
[DEBUG] First run: scanning since date 18-Jan-2025
[DEBUG] Found 23 messages to process: [b'49146', b'49147', b'49148', b'49149', b'49150', b'49151', b'49152', b'49153', b'49154', b'49155', b'49156', b'49157', b'49158', b'49159', b'49160', b'49161', b'49162', b'49163', b'49164', b'49165', b'49166', b'49167', b'49168']
[DEBUG] Processing sequence number: b'49146'
[DEBUG] FETCH response: b'49146 (UID 50196)'
[DEBUG] FETCH line to parse: 49146 (UID 50196)
[DEBUG] Parsed UID: 50196
[DEBUG] Valid UID Found: 50196
[DEBUG] Successfully fetched message for UID 50196
[UID 50196] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, sender is not upset, and there does not seem to be a critical issue mentioned.
[DEBUG] Processing sequence number: b'49147'
[DEBUG] FETCH response: b'49147 (UID 50197)'
[DEBUG] FETCH line to parse: 49147 (UID 50197)
[DEBUG] Parsed UID: 50197
[DEBUG] Valid UID Found: 50197
[DEBUG] Successfully fetched message for UID 50197
[UID 50197] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49148'
[DEBUG] FETCH response: b'49148 (UID 50198)'
[DEBUG] FETCH line to parse: 49148 (UID 50198)
[DEBUG] Parsed UID: 50198
[DEBUG] Valid UID Found: 50198
[DEBUG] Successfully fetched message for UID 50198
[UID 50198] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, sender is not upset, and there doesn't seem to be a critical issue presented in the content.
[DEBUG] Processing sequence number: b'49149'
[DEBUG] FETCH response: b'49149 (UID 50199)'
[DEBUG] FETCH line to parse: 49149 (UID 50199)
[DEBUG] Parsed UID: 50199
[DEBUG] Valid UID Found: 50199
[DEBUG] Successfully fetched message for UID 50199
[UID 50199] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, the sender is not upset, and there is no critical issue mentioned in the message.
[DEBUG] Processing sequence number: b'49150'
[DEBUG] FETCH response: b'49150 (UID 50200)'
[DEBUG] FETCH line to parse: 49150 (UID 50200)
[DEBUG] Parsed UID: 50200
[DEBUG] Valid UID Found: 50200
[DEBUG] Successfully fetched message for UID 50200
[UID 50200] No escalation: DOESNOTAPPLY. The email lacks sufficient content for an escalation.
[DEBUG] Processing sequence number: b'49151'
[DEBUG] FETCH response: b'49151 (UID 50201)'
[DEBUG] FETCH line to parse: 49151 (UID 50201)
[DEBUG] Parsed UID: 50201
[DEBUG] Valid UID Found: 50201
[DEBUG] Successfully fetched message for UID 50201
[UID 50201] Escalation triggered: Security alert
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49152'
[DEBUG] FETCH response: b'49152 (UID 50202)'
[DEBUG] FETCH line to parse: 49152 (UID 50202)
[DEBUG] Parsed UID: 50202
[DEBUG] Valid UID Found: 50202
[DEBUG] Successfully fetched message for UID 50202
[UID 50202] Escalation triggered: Delivery Status Notification (Failure)
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49153'
[DEBUG] FETCH response: b'49153 (UID 50203)'
[DEBUG] FETCH line to parse: 49153 (UID 50203)
[DEBUG] Parsed UID: 50203
[DEBUG] Valid UID Found: 50203
[DEBUG] Successfully fetched message for UID 50203
[UID 50203] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49154'
[DEBUG] FETCH response: b'49154 (UID 50204)'
[DEBUG] FETCH line to parse: 49154 (UID 50204)
[DEBUG] Parsed UID: 50204
[DEBUG] Valid UID Found: 50204
[DEBUG] Successfully fetched message for UID 50204
[UID 50204] Escalation triggered: my server lollipop is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49155'
[DEBUG] FETCH response: b'49155 (UID 50205)'
[DEBUG] FETCH line to parse: 49155 (UID 50205)
[DEBUG] Parsed UID: 50205
[DEBUG] Valid UID Found: 50205
[DEBUG] Successfully fetched message for UID 50205
[UID 50205] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49156'
[DEBUG] FETCH response: b'49156 (UID 50206)'
[DEBUG] FETCH line to parse: 49156 (UID 50206)
[DEBUG] Parsed UID: 50206
[DEBUG] Valid UID Found: 50206
[DEBUG] Successfully fetched message for UID 50206
[UID 50206] Escalation triggered: now doomfire is down too!
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49157'
[DEBUG] FETCH response: b'49157 (UID 50207)'
[DEBUG] FETCH line to parse: 49157 (UID 50207)
[DEBUG] Parsed UID: 50207
[DEBUG] Valid UID Found: 50207
[DEBUG] Successfully fetched message for UID 50207
[UID 50207] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49158'
[DEBUG] FETCH response: b'49158 (UID 50208)'
[DEBUG] FETCH line to parse: 49158 (UID 50208)
[DEBUG] Parsed UID: 50208
[DEBUG] Valid UID Found: 50208
[DEBUG] Successfully fetched message for UID 50208
[UID 50208] Escalation triggered: pants is down now
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49159'
[DEBUG] FETCH response: b'49159 (UID 50209)'
[DEBUG] FETCH line to parse: 49159 (UID 50209)
[DEBUG] Parsed UID: 50209
[DEBUG] Valid UID Found: 50209
[DEBUG] Successfully fetched message for UID 50209
[UID 50209] Escalation triggered: server05 down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49160'
[DEBUG] FETCH response: b'49160 (UID 50210)'
[DEBUG] FETCH line to parse: 49160 (UID 50210)
[DEBUG] Parsed UID: 50210
[DEBUG] Valid UID Found: 50210
[DEBUG] Successfully fetched message for UID 50210
[UID 50210] No escalation: DOESNOTAPPLY (The sender has asked for a phone call instead of specifying the issue in detail, so it doesn't appear to be urgent or critical at first glance.)
[DEBUG] Processing sequence number: b'49161'
[DEBUG] FETCH response: b'49161 (UID 50211)'
[DEBUG] FETCH line to parse: 49161 (UID 50211)
[DEBUG] Parsed UID: 50211
[DEBUG] Valid UID Found: 50211
[DEBUG] Successfully fetched message for UID 50211
[UID 50211] Escalation triggered: my server is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49162'
[DEBUG] FETCH response: b'49162 (UID 50212)'
[DEBUG] FETCH line to parse: 49162 (UID 50212)
[DEBUG] Parsed UID: 50212
[DEBUG] Valid UID Found: 50212
[DEBUG] Successfully fetched message for UID 50212
[UID 50212] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49163'
[DEBUG] FETCH response: b'49163 (UID 50213)'
[DEBUG] FETCH line to parse: 49163 (UID 50213)
[DEBUG] Parsed UID: 50213
[DEBUG] Valid UID Found: 50213
[DEBUG] Successfully fetched message for UID 50213
[UID 50213] Escalation triggered: this is getting bad
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49164'
[DEBUG] FETCH response: b'49164 (UID 50214)'
[DEBUG] FETCH line to parse: 49164 (UID 50214)
[DEBUG] Parsed UID: 50214
[DEBUG] Valid UID Found: 50214
[DEBUG] Successfully fetched message for UID 50214
[UID 50214] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49165'
[DEBUG] FETCH response: b'49165 (UID 50215)'
[DEBUG] FETCH line to parse: 49165 (UID 50215)
[DEBUG] Parsed UID: 50215
[DEBUG] Valid UID Found: 50215
[DEBUG] Successfully fetched message for UID 50215
[UID 50215] Escalation triggered: server zebra 05 is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49166'
[DEBUG] FETCH response: b'49166 (UID 50216)'
[DEBUG] FETCH line to parse: 49166 (UID 50216)
[DEBUG] Parsed UID: 50216
[DEBUG] Valid UID Found: 50216
[DEBUG] Successfully fetched message for UID 50216
[UID 50216] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49167'
[DEBUG] FETCH response: b'49167 (UID 50217)'
[DEBUG] FETCH line to parse: 49167 (UID 50217)
[DEBUG] Parsed UID: 50217
[DEBUG] Valid UID Found: 50217
[DEBUG] Successfully fetched message for UID 50217
[UID 50217] Escalation triggered: help
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49168'
[DEBUG] FETCH response: b'49168 (UID 50218)'
[DEBUG] FETCH line to parse: 49168 (UID 50218)
[DEBUG] Parsed UID: 50218
[DEBUG] Valid UID Found: 50218
[DEBUG] Successfully fetched message for UID 50218
[UID 50218] Escalation triggered: server is down
Alert sent to xxxx@hotmail.com
[DEBUG] Updating last scanned UID to 50218
[DEBUG] Attempting to update last scanned UID to 50218
[DEBUG] Last scanned UID successfully updated to 50218
Example of an alert message
Escalation Triggered
Date: Sat, 18 Jan 2025 21:00:16 +0000
From: Gordon Buchan <gordonhbuchan@hotmail.com>
To: "gordonhbuchan@gmail.com" <gordonhbuchan@gmail.com>
CC:
Subject: server is down
Body: server down help please
Reason: Escalation Reason: This email indicates that there is a critical issue (server downtime).
Creating a systemd service to run the doicare script automatically
Enter the following command:
nano /etc/systemd/system/doicare.service
Use the nano editor to add the following text (change values to match your path):
In this procedure we install the open source program OpenVPN on a server running on Linux to create a virtual private network (VPN) authenticated against Active Directory with two-factor authentication (2FA) enabled Google Authenticator.
Business case
A Linux server running OpenVPN server software can replace a Windows server or other commercial solution for the VPN server role in the enterprise, reducing software licensing costs and improving security and stability.
Authenticating connections to the VPN server using client certificates and Google Authenticator one-time passwords (OTPs)
Verifying client-side VPN certificates to authenticate a VPN connection
The VPN server will verify client digital certificates as one of the authentication methods.
Using Google Authenticator to obtain a one-time password (OTP) to authenticate a VPN connection
The VPN server will verify the one-time password (OTP) generated by Google Authenticator as one of the authentication methods.
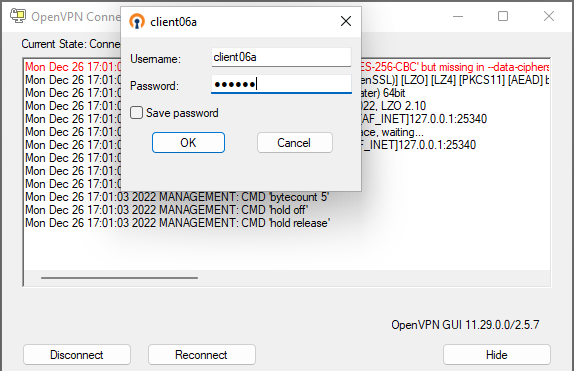
Entering the OTP from Google Authenticator as the password for the VPN connection
To access the network, help desk clients will:
Enter their local network file share or Active Directory username as the username for the VPN connection.
Enter the OTP from Google Authenticator as the password for the VPN connection.
Not verifying a local password authentication module (PAM) or Active Directory password to authenticate a VPN connection
This procedure does not verify a PAM or Active Directory password to authenticate the VPN connection.
There are ways of prompting for a username, and a password, and an OTP from Google Authenticator. However, some of these are difficult to integrate with with client VPN connector software, which do not support a second password field. Some approaches ask the help desk client to enter a system password and the OTP as a combined password, but this can be confusing for help desk clients.
This procedure was tested on Ubuntu Linux 22.04 LTS
Deploying the VPN server as a physical or virtual machine
Deploy OpenVPN on a physical Linux server or on a virtual Linux server hosted as a virtual machine (VM), using KVM on Linux, Hyper-V, VMware, or VirtualBox on Windows, or Parallels using MacOS.
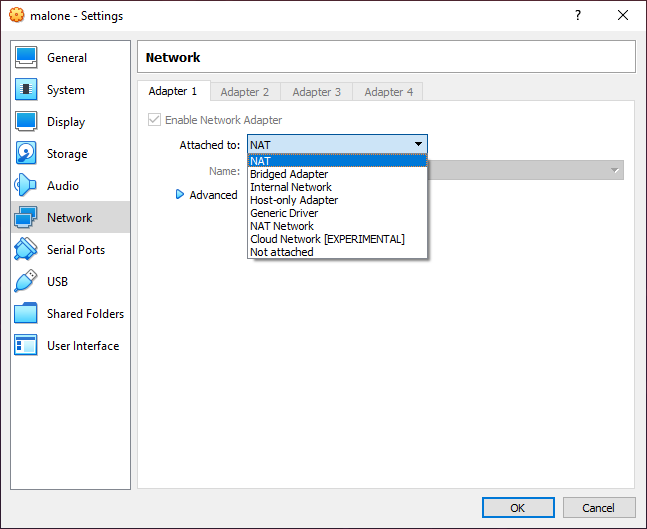
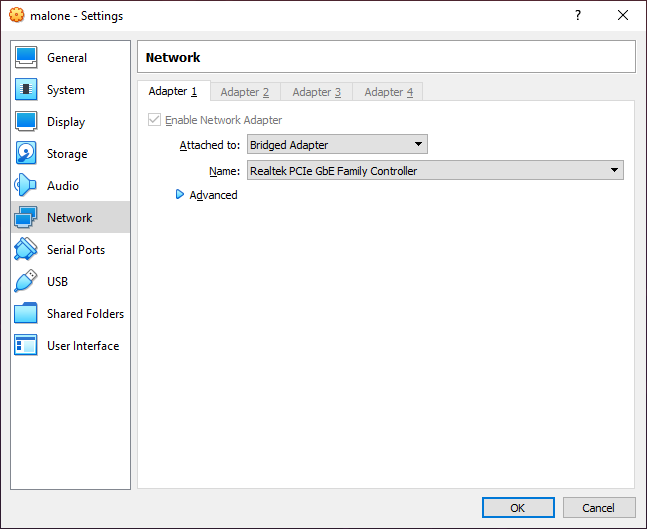
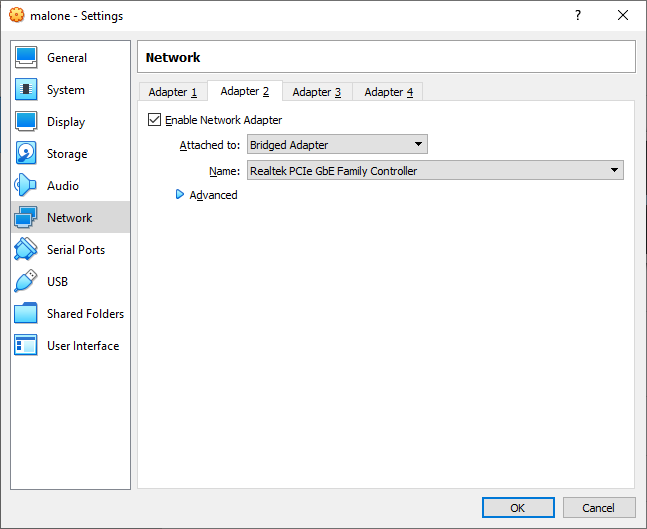
Adding a macvtap or bridge mode network adapter to a virtual machine
For KVM, add a macvtap network adapter to the automation server. For Hyper-V, VMware, VirtualBox or Parallels, add a bridge mode network adapter. This will allow the VPN server to access the same network as the server’s hypervisor host.
Assigning a static IP address to the server that will host the VPN
Assign a static IP to the VPN server.
Assigning a permanent host name to a dynamic host configuration protocol (DHCP) public-facing IP address
Most residential Internet connections have a dynamic host configuration protocol (DHCP) public-facing IP address, which can change over time. You can use a service like no-ip.com to associate a permanent host name such as permhostname.ddns.net to a host with a dynamic IP address:
cd /etc/openvpn/server
nano google-authenticator.sh
#!/usr/bin/bash
# this script written by OpenAI ChatGPT
# see References section for prompt
# check if the user has provided a username and password
if [ -z "$username" -o -z "$password" ]; then
exit 1
fi
# get the user's secret key from the Google Authenticator app
secret_key=$(grep "^$username:" /etc/openvpn/server/google-authenticator.keys | cut -d: -f2)
# check if the user has a secret key
if [ -z "$secret_key" ]; then
exit 1
fi
# generate a six-digit code using the secret key and the current time
code=$(oathtool --totp -b "$secret_key")
# compare the generated code with the password provided by the user
if [ "$code" = "$password" ]; then
exit 0
else
exit 1
fi
Press Ctrl-X to save and exit the file.
Enter the following command:
chmod 755 google-authenticator.sh
Restarting the OpenVPN server
From a root shell, enter the following command:
systemctl restart openvpn-server@server
Downloading the OpenVPN client profile
Use the FileZilla file transfer client to download the OpenVPN client profile:
Use a text editor to load the OpenVPN client profile. Add the following text to the bottom of the file:
auth-user-pass
Save and exit the file.
Downloading and Installing the Google Authenticator app on a help desk client’s smartphone
Visit the Apple App Store or the Google Play Store. Search for “google authenticator” and download the app:
Click on “Get started”:
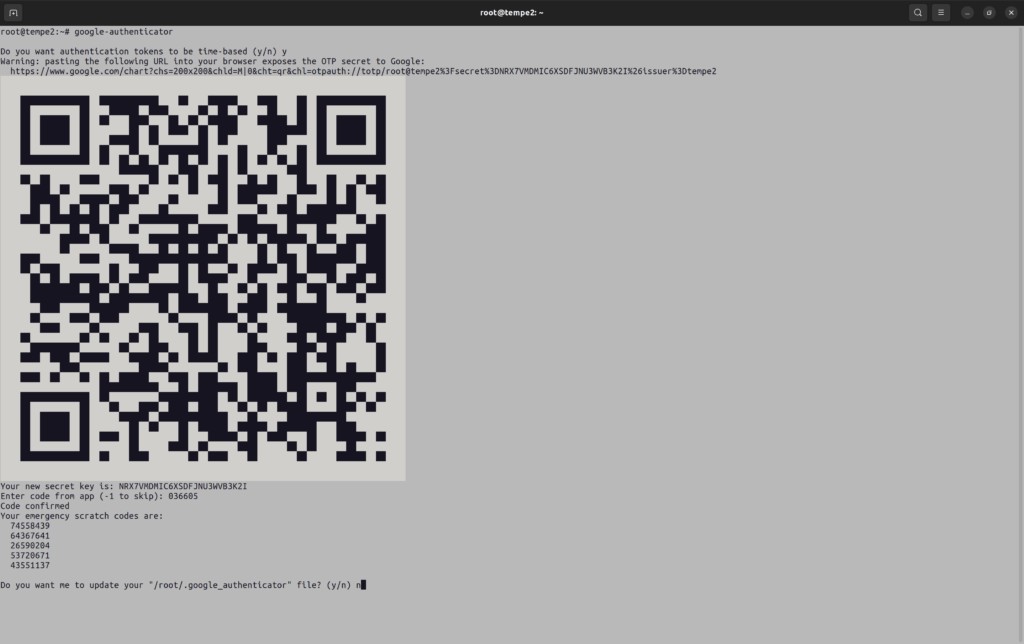
Running the google-authenticator command on the server to enrol the help desk client’s Google Authenticator app
Open a terminal window as root, and make the terminal window full-screen. Enter the following command:
google-authenticator
Scanning the QR code into the Google Authenticator smartphone app
Click on “Scan a QR code” then click on “OK” to allow the app to access the camera:
Look at the one-time code shown on the Google Authenticator app:
Enter the code in the Terminal window in the field: “Enter code from the app (-1 to skip):”
Enter “n” to the question: “Do you want me to update your “/root/.google_authenticator file? (y/n):”
Creating the /etc/openvpn/server/google-authenticator.keys file and entering the secret key created during enrolment of the help desk client’s Google Authenticator app.
Enter the following commands:
cd /etc/openvpn/server nano google-authenticator.keys
Add an entry to the file in with the format “username: yournewsecretkey”:
client06a:NRX7VMDMIC6XSDFJNU3WVB3K2I
Press Ctrl-X to save and exit the file.
A note re automation
Should this process be automated further? Yes. The google-authenticator program on the server could be scripted so that the client’s username and secret code could be added to the /etc/openvpn/server/google-authenticator.keys file.
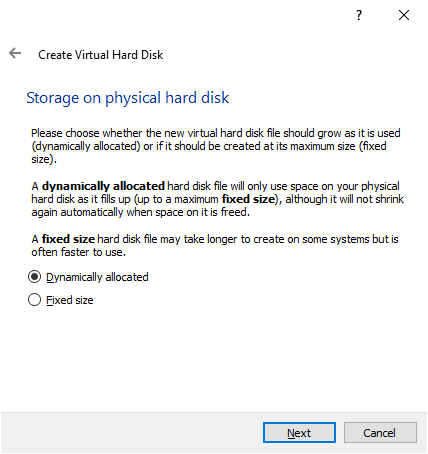
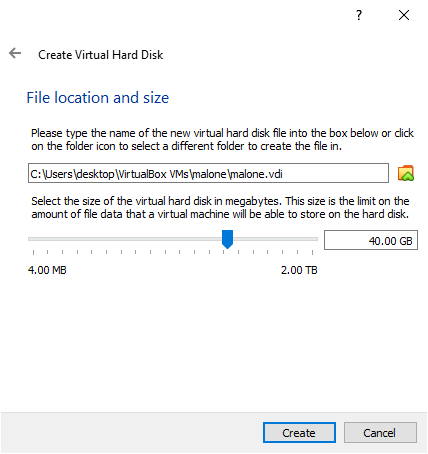
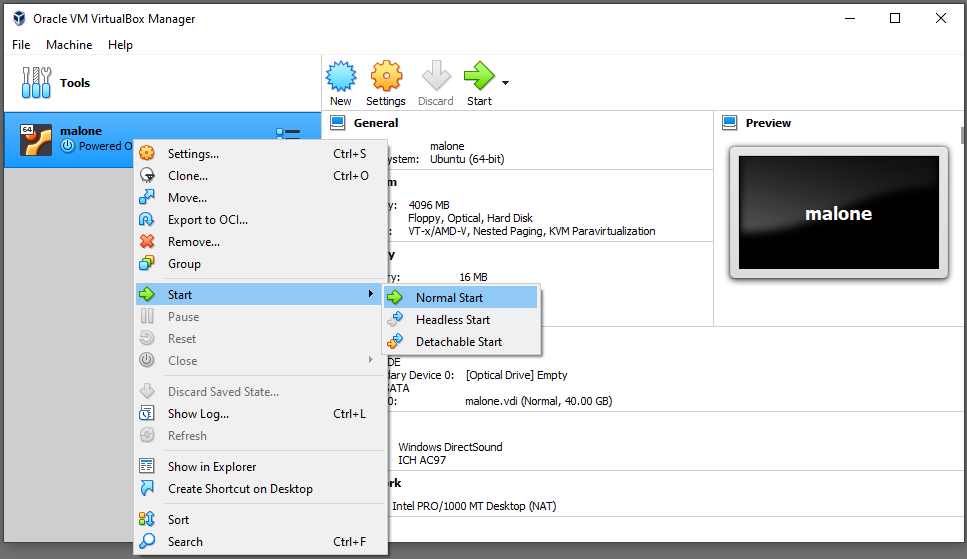
In this post, we use the server automation tools Ansible, Terraform, Docker, and Kubernetes to create and configure virtual machines (VMs) to host an on-premises Kubernetes cluster.
Understanding infrastructure
Infrastructure refers to computing resources used to store, transform, and exchange data. A new approach to software development called DevOps deploys applications across distributed systems consisting of multiple physical and virtual machines.
Understanding DevOps
DevOps is an approach to software development and system administration that views system administration as a task to be automated, so that software developers are not dependent on the services of a system administrator when they deploy software to server infrastructure.
DevOps tools automate the creation and deployment of servers to create a distributed software infrastructure on which software can be deployed and run on multiple computers whether physical or virtual.
Understanding the difference between cloud and on-premises (“onprem”) virtualization servers
The term “cloud” refers to computing services that are offsite, outsourced, and virtualized. These cloud services are provided by companies including Amazon AWS, Google GCP, Microsoft Azure, and Digital Ocean.
The term “On-premises” (“onprem”) refers to computing services that are onsite, in-house, and virtualized. Onprem virtualization servers can provide the same software environment as cloud providers. Onprem server infrastructure can be used to develop and test new software before it is deployed to a public cloud.
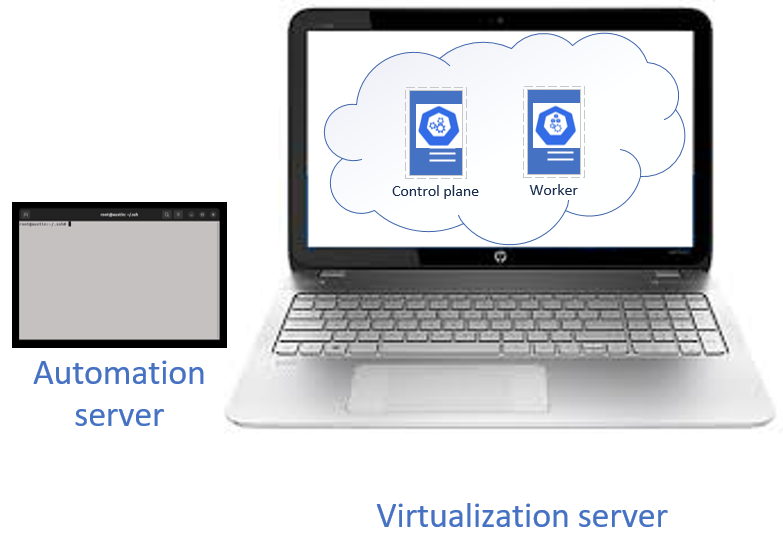
Overview of the system to be constructed
Understanding the virtualization server
Virtual machines require a physical machine containing processors, memory, and storage. For this exercise, we will reformat a circa 2015 laptop (i7-4712HQ, 16GB RAM, 1TB SSD) with Ubuntu Linux 22.04 LTS as an on-premises virtualization host.
Understanding KVM virtualization
KVM creates a hypervisor virtualization host on a Linux server. A KVM hypervisor can host multiple virtual machine (VM) guests.
Understanding Terraform
Terraform can run scripts that automate the creation of virtual machines, on public clouds such as Amazon AWS, Google GCP, and Digital Ocean, as well as on on-premises (“onprem”) virtualization hosts including KVM.
Understanding the libvirt provider software
The libvirt provider software enables Terraform to automate the creation of virtual machines on KVM hypervisor hosts.
Understanding Ansible
Ansible can run scripts that automate server administration tasks. In this exercise, multiple Ansible scripts will be executed to use Terraform to create virtual machine (VM) servers, on which software will be deployed and configured, creating a Kubernetes cluster.
Understanding virtual machine (VM) guests
A virtual machine (VM) guest is a server that emulates hardware as a software image, using a subset of the hypervisor host’s processor cores, memory, and storage to create a distinct computer environment, with its own software libraries, network address, and password or key entry system.
Understanding Docker software containers
Docker containers are software containers created by the docker-compose command. A Docker container has its own software libraries, network address, and password or key entry system, but comparisons between Docker containers and virtual machines (VMs) are discouraged.
Understanding Kubernetes
Kubernetes is software that allows you to create a high-availability cluster consisting of a control plane server and one or more worker servers. Kubernetes allows for software to be deployed as containers stored in pods, running on clusters, running on nodes.
Containers
Software is organized within Docker containers. A Docker container is a self-contained computing environment with its own libraries, IP address, and SSH password or key.
Pods
Pods are a unit of computing that contain one or more containers. Pods execute on clusters, which are intermediate interfaces that distribute computing tasks across control plane and worker nodes, running on virtual machine servers.
Clusters
A cluster is an addressable interface that allows for the execution of Kubernetes Pods across a distributed system of control plane and worker nodes.
Nodes
In Kubernetes, a node is the physical or virtual machine that hosts the control plane role or worker role in a distributed Kubernetes cluster. In this exercise the nodes will be hosted on KVM virtual machines (VMs).
Understanding the automation server
The automation server is a Linux server separate from the virtualization server. The automation server can be a physical or virtual machine.
Tip: avoid running operations like this from your baremetal desktop. These operations involve hosts files and SSH keys for server access, and should be isolated if possible. Consider creating a virtual machine for this role using a hypervisor such as KVM on Linux, VirtualBox on Windows, or Parallels on MacOS. Use Ubuntu Linux 22.04 LTS.
Entering commands as root
This procedure assumes that you are entering commands as root. Escalate to the root user:
sudo su
Preparing the virtualization server 1/3
The virtualization server should be a minimal build: do a fresh format of Ubuntu Linux 22.04 LTS.
Using a wired network connection
If possible, use a wired Ethernet connection for the network connection on the hypervisor. This simplifies advanced operations like iptables forwarding and makes possible the later use of macvtap adapters for connecting in the hypervisor host networking space.
Setting a static IP address
Set a static IP address for the network connection of the virtualization server. Reboot.
Installing software on the virtualization server
From a root shell on the virtualization server, enter the following command:
Configuring the SSH server on the virtualization server
From a root shell on the virtualization server, enter the following commands:
cd /etc/ssh
Use the nano editor to create the following text file:
nano sshd_config
uncomment and replace the following line:
PermitRootLogin yes
Creating a root password
sudo su
passwd
Preparing the automation server 1/2
Configure a virtual machine on a different physical machine than the virtualization server. Use Ubuntu Linux 22.04 LTS.
Adding a macvtap or bridge mode network adapter
For KVM, add a macvtap network adapter to the automation server. For VirtualBox or Parallels, add a bridge mode network adapter. This will allow the automation server to access internal subnets on the virtualization server via an ip route command.
Installing software and downloading Ansible scripts on the automation server
From a root shell on the automation server, enter the following commands:
apt install ansible git openssh-server net-tools iptraf-ng
cd /root
mkdir tmpops
cd tmpops
git clone https://github.com/kubealex/libvirt-k8s-provisioner.git
Creating the Ansible hosts file
cd /etc
mkdir ansible
cd ansible
Use the nano editor to create the following text file (use the IP address of the virtualization server in your setup):
nano hosts
contents:
[vm_host]
192.168.56.60
Creating an SSH key pair
From a root shell on the automation server, enter the following command:
ssh-keygen -f /root/.ssh/id_rsa -q -N ""
When prompted for a passphrase, press Enter and provide a blank value.
Copying the SSH public key to the virtualization server
From a root shell on the automation server, enter the following commands (substitute the IP address of the virtualization server in your setup):
cd /root/.ssh
rsync -e ssh -raz id_rsa.pub root@192.168.56.60:/root/.ssh/authorized_keys
Preparing the virtualization server 2/3
Verifying the automation server’s public key on the virtualization server
From a root shell on the virtualization server, enter the following commands:
Testing that the automation server can connect to the virtualization server using a public SSH key
From the automation server, enter the folowing command (substitute the IP address of your virtualization server):
ssh root@192.168.56.60
Note: If you are able to login without supplying a password, you have succeeded.
Using Ansible to automate operations
Ansible can run scripts called playbooks to perform automated server administration tasks. Ansible playbook scripts will use Terraform to create and configure virtual machines (VMs) on which a Kubernetes cluster will be installed.
A note about the libvirt-k8s-provisioner project
The libvirt-k8s-provisioner project provides a set of scripts that use Ansible and Terraform to create virtual machines (VMs) and to deploy a Kubernetes cluster.
Modifying the libvirt-k8s-provisioner vars file
cd /root/tmpops/libvirt-k8s-provisioner/vars
nano k8s_cluster.yml
Installing the collection requirements for Ansible operations
From a root shell on the virtualization server, enter the following commands:
cd /root/tmpops/libvirt-k8s-provisioner
ansible-galaxy collection install -r requirements.yml
Running the Ansible playbook to create and configure virtual machines on the virtualization host 1/2
From a root shell on the virtualization server, enter the following commands:
ansible-playbook main.yml
The task sequence will end with this error:
fatal: [k8s-test-worker-0.k8s.test]: FAILED! => {"changed": false, "elapsed": 600, "msg": "timed out waiting for ping module test: Failed to connect to the host via ssh: ssh: Could not resolve hostname k8s-test-worker-0.k8s.test: Name or service not known"}
fatal: [k8s-test-master-0.k8s.test]: FAILED! => {"changed": false, "elapsed": 600, "msg": "timed out waiting for ping module test: Failed to connect to the host via ssh: ssh: Could not resolve hostname k8s-test-master-0.k8s.test: Name or service not known"}
Note: we will recover from this error in a later step.
Preparing the virtualization server 3/3
From a root shell on the virtualization server, enter the following command:
virsh net-dhcp-leases k8s-test
Information about the virtual machines in the k8s-test network will be displayed:
root@henderson:/home/desktop# virsh net-dhcp-leases k8s-test
Expiry Time MAC address Protocol IP address Hostname Client ID or DUID
--------------------------------------------------------------------------------------------------------------------------------------------------------
2022-07-29 07:21:42 52:54:00:4a:20:99 ipv4 192.168.200.99/24 k8s-test-master-0 ff:b5:5e:67:ff:00:02:00:00:ab:11:28:1f:a1:fb:24:5c:f5:70
2022-07-29 07:21:42 52:54:00:86:29:8f ipv4 192.168.200.28/24 k8s-test-worker-0 ff:b5:5e:67:ff:00:02:00:00:ab:11:9e:22:e1:40:72:21:cf:9d
Take note of the IP addresses starting with 192.168.200, these values will be needed in a later configuration step.
Understanding the need for IP forwarding on the virtualization server
By default, virtual machines are created with IP addresses in the 192.168.200.x subnet. This subnet is accessible within the virtualization server.
In order to make the 192.168.200.x subnet accessible to the automation server, we need to create a gateway router using iptables directives on the virtualization server.
In a later step, we will add a default route for the 192.168.200.x subnet on the automation server, allowing it to resolve IP addresses in that subnet.
Enabling IP forwarding for the 192.168.200.x subnet
From a root shell on the virtualization server, enter the following commands:
Use the nano editor to create the following text file:
cd /etc
nano sysctl.conf
Add the following line to the end of the sysctl.conf file:
net.ipv4.ip_forward = 1
Enter this command:
sysctl -p
Use the nano editor to create the following text file (substitute the wanadaptername and wanadapterip for those of the virtualization server in your setup):
From a root shell on the automation server, enter the following command (substitute the wanadaptername (dev) and wanadapterip for those of the virtualization server in your setup):
ip route add 192.168.200.0/24 via 192.168.56.60 dev enp0s3
Note: add invocation to /etc/rc.local for persistence.
Testing the IP routing from the automation server to the 192.168.200.x subnet
Ping one of the IP addresses you observed in the preceding step “Preparing the virtualization server 3/3” (Substitute one of the IP addresses in your setup):
ping 192.168.200.99
Running the Ansible playbook to create and configure virtual machines on the virtualization host 2/2
From a root shell on the automation server, enter the following commands:
cd /root/tmpops/libvirt-k8s-provisioner
ansible-playbook main.yml
Verifying that the Ansible task sequence has completed without errors
In this procedure we create a network file share by integrating the open source program Samba running on Linux with Active Directory to authenticate access to the network file share.
Business case
A computer running Linux and Samba can create a network file share authenticating against a company’s Active Directory. This means that a Linux server and Samba network file share software can replace a Windows server for the network file share role in the enterprise, reducing software licensing costs and improving security and stability.
This procedure was tested on Ubuntu Linux 22.04 LTS
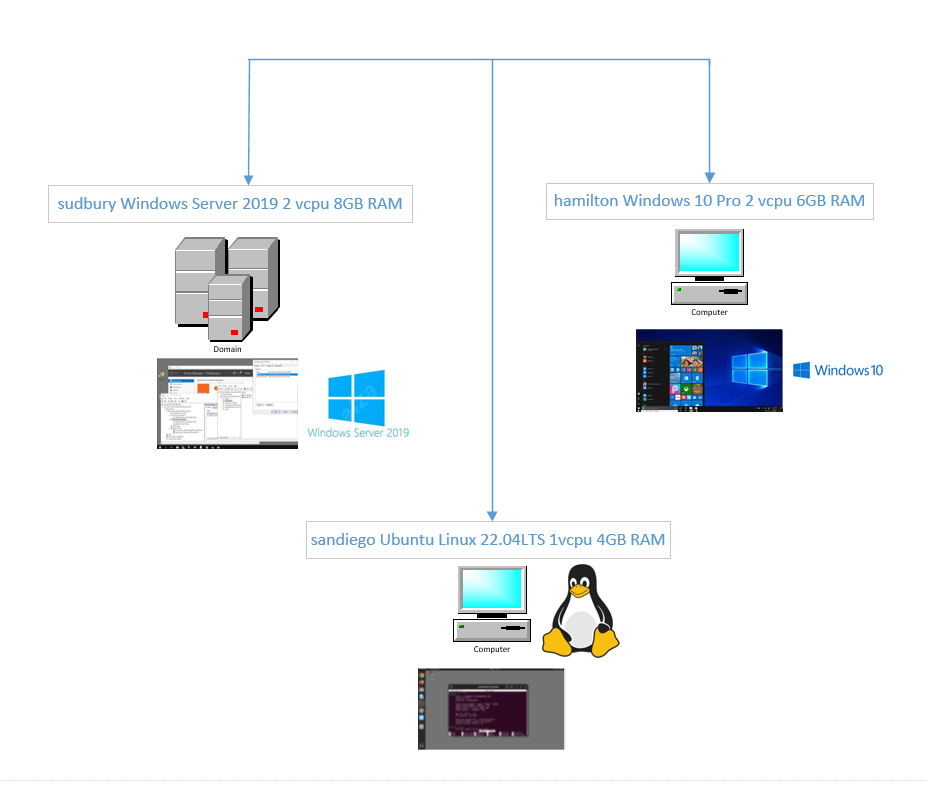
This procedure was tested on a network of 3 virtual machines, each running in bridge mode, on different hypervisor hosts.
sudbury
Windows Server 2019 acting as Active Directory controller for the clarkcounty.gordonbuchan.com domain.
sandiego
Ubuntu Linux 22.04LTS desktop joined to the clarkcounty.gordonbuchan.com domain, authenticating access to a network file share enabled by Samba and Winbind against the Active Directory controller for the domain clarkcounty.gordonbuchan.com on sudbury.
hamilton
Windows 10 Pro workstation joined to the clarkcounty.gordonbuchan.com domain.
Understanding Active Directory
Active Directory is commercial software developed by Microsoft that runs primarily on Windows Server. Active Directory can authenticate users and groups of users, and can control access to resources like network file shares and “Single Sign-On” (SSO) login to computers connected to the network.
Understanding Samba
Samba is open source free software that enables a Linux server to provide a network file share that can be accessed by Windows computers.
A note re Samba’s included Active Directory functionality
Samba itself is able to act as an Active Directory controller and can implement a subset of Active Directory’s features. This post assumes that you are authenticating against an Active Directory controller running on Windows Server.
Understanding Winbind
Winbind is software that enables Samba to integrate with Active Directory to authenticate access to a network file share.
Understanding System Security Services Daemon (SSSD)
SSSD is a technology that enables Active Directory integration for Linux workstations. In practice, it is difficult to integrate SSSD with Samba for Active Directory authentication in a stable fashion. There are some approaches to SSSD which incorporate Winbind for a hybrid approach. This procedure will focus on using Winbind, and without using SSSD.
Choosing Winbind over SSSD for a network file share authenticaticated against Active Directory
This procedure will use Winbind to enable Samba to integrate with Active Directory to create a network file share authenticated against Active Directory.
Objectives
Access to the network file share authenticated against Active Directory.
The network file share must be accessible to workstations with “Enable insecure guest logins” set to “Disabled.”
The network file share must observe ACL and allow overrides by Windows clients for ownership and permissions.
(Single-Sign-On (SSO) and SSSD will be addressed in a later procedure.)
Creating the Active Directory group example_group and adding members to the group
Entering commands as root
This procedure assumes that you are logged in as the root user of the Linux server.
Escalate to the root user:
sudo su
Replacing the example realm/domain name with your realm/domain name
Please replace the sample realm/domain name clarkcounty.gordonbuchan.com with your realm/domain name.
Note: for the files /etc/krb5.conf and /etc/samba/smb.conf, the realm/domain name must be in UPPERCASE letters
The realm/domain name must be in UPPERCASE letters. This includes the long version CLARKCOUNTY.GORDONBUCHAN.COM and short version CLARKCOUNTY of the realm/domain name.
Web presence step by step is a series of posts that show you to how to build a web presence.
This post describes how to install Linux as a virtual machine (VM) guest on a Windows computer, by installing a program called VirtualBox.
Installing Linux as a VM guest allows you to explore Linux as a desktop or server operating system from an existing Windows computer, without reformatting.
VirtualBox is a hypervisor
The software that enables a computer to host a virtual machine as a guest is called a hypervisor. The hypervisor we will install in this blog post is called VirtualBox, an open source application available free of charge.
Using a virtual machine (VM) guest as a web, database, or file sharing server for local development and testing
A VM guest performs well in server roles likes web, database, and file sharing. VMs can be used for offline development and testing of websites and web-based applications, which are later deployed to public-facing web servers.
A VM guest can be used to deploy an internal or public-facing server with an application such as WordPress or Nextcloud.
Should you use a VirtualBox VM guest server for production?
Probably not. VirtualBox is great for testing, experiments, learning. However, if you are going into production, to run an essential task for a business, you should consider a more formal deployment using a platform like Linux KVM or Windows Server Hyper-V for an internal deployment, or to a public cloud like Digital Ocean or AWS for a public-facing deployment.
Who should consider using a VirtualBox VM guest server?
VirtualBox enables people to experiment with Linux, without making a commitment to modifying their existing Windows computer.
VirtualBox is great for students — anyone learning software development can host their own fully-functioning Linux server, allowing them to build prototype servers, containers, and software development environments.
Using a VM guest as a graphical user interface (GUI) desktop
A VM guest can function as a graphical desktop, allowing you to use the guest operating system in a sized window, or in full-screen mode. For example, you can connect to another network via VPN from a VM guest, while the host computer running Windows remains connected to its original network.
Limitations of a VM guest GUI desktop
VMs have some limitations: they are not well-suited to GPU-intensive tasks like video editing software or gaming, for example. YouTube video will be choppy.
Installing Ubuntu desktop Linux as a guest VM under VirtualBox
Adjusting resolution
Adjusting window size
Switching to full screen mode
Enabling audio
Network considerations at the hypervisor level
Understanding communications between the host and the VM guest
The VM guest running under VirtualBox is a distinct and separate computer from the machine that hosts it. VirtualBox enables network communication between the VM guest and the Internet, via the network connection of the host.
VirtualBox also enables network communication between the VM guest and the host. For example, if you have a web server running on your VM guest, you can connect to it from your host’s desktop using a web browser or a terminal program like KiTTY for SSH.
Understanding the difference between network address translation (NAT) mode vs bridge mode
Network address translation (NAT) mode
By default, a VM guest is created with a network adapter configured to connect to the Internet via the Internet connection of its host.
A host can communicate with a VM guest via a NAT mode network connection
The host and the VM guest are able to communicate with each other. Computers other than the host cannot see or initiate a network connection with the VM guest.
Creating a NAT network to permit communications between the host and the VM guest
Making a VM guest visible and accessible to other computers on the network to which the host is connected
A VM guest can be made visible and accessible to other computers on the network via a bridge mode network connection, or via port forwarding.
Bridge mode
The network adapter for a VM guest can be configured in “bridge mode” which permits the VM to connect directly to the same network as the host. In this mode, a VM guest can request an IP address or use an IP address in the same subnet as the host and other computers connected to the same network.
A host cannot communicate with a VM guest via a bridge mode network connection
Due to the way that a bridge mode connection is configured to use the network connection of the host, the link permits communication between the VM guest and the outside world, but not between the VM guest and the host itself.
Adding an additional network adapter
(Note: the VM must be powered down in order to add a network adapter.)
Understanding port forwarding
VirtualBox will offer to open a hole on the host’s firewall. Click on “Allow access”:
After upgrading from Ubuntu 20.10 to Ubuntu 21.04, screen sharing (VNC server) is no longer functioning correctly.
Update 2023/11/02: on Ubuntu 22.04, in some situations, the x11vnc server will start on port 5901/tcp, rather than the default 5900/tcp, even if legacy VNC support is disabled.
x11vnc is an effective replacement for Vino and gnome-remote-desktop
This post describes how to install x11vnc, and describes how to create a script that runs at Gnome desktop login that invokes x11vnc with the necessary command line options.
Vino was replaced by gnome-remote-desktop, but gnome-remote-desktop does not function correctly in Ubuntu 21.04
Vino, the VNC server previously used by Gnome, has been deprecated. Vino has been replaced by gnome-remote-desktop, but as currently integrated, gnome-remote-desktop does not function correctly in Ubuntu 21.04.
When configured using the standard Gnome control panel settings (Settings, Sharing, Screen Sharing):
This is the error that appears when trying to connect, in both xorg and wayland:
This is a good reminder of why one should use an LTS release for production servers
A good suggested practice is to run LTS releases on production servers, but run recent releases on workstation laptops. This allows for issues to be identified and workarounds devised before the next LTS release, in case the problem persists in the next LTS release.
Why would one want to access the Graphical User Interface (GUI) desktop of a Linux server?
For some server tasks, it is helpful to be able to access the GUI desktop of the server via a remote viewer. For example, you may need to install a GUI operating system as a guest, and access its GUI desktop from the console of your server’s GUI desktop.
Disabling Wayland
Wayland is an alternative to the xorg windows system. One day, it will be terrific. For now, it does not work with x11vnc or other important applications like TeamViewer.
sudo su
cd /etc/gdm3
nano custom.conf
# Uncomment the line below to force the login screen to use Xorg
WaylandEnable=false
reboot
A reminder about the firewall and opening port 5900/tcp
From a shell window, enter the following commands:
sudo su
ufw allow 5900/tcp
ufw allow 5901/tcp
exit
Disabling the existing (broken) screen sharing server
Settings, Sharing, Screen Sharing:
Installing the x11vnc package
From a shell window, enter the following commands:
sudo su
apt install x11vnc
exit
Creating a password for x11vnc
From a shell as the user that owns the Gnome desktop session, enter these commands. When prompted, supply a password:
whoami
x11vnc -storepasswd
A friendly warning about security
Different situations can accept different levels of risk. The VNC protocol as implemented, sends data as cleartext over a network connection. This may be acceptable over a local area network, particularly if you have VLAN segmentation and good wifi encryption enabled on your house Local Area Network (LAN).
Do not even consider sending this kind of unencrypted traffic over the public Internet. Use a VPN, or redirect the connection via SSH tunnelling.
Starting the server manually
From a shell as the user that owns the Gnome desktop session, enter these commands. When prompted, supply a password:
From a shell window, enter the following commands:
sudo su
apt install net-tools
ifconfig
exit
(Note: the command:
ip a
provides an equivalent result. But ifconfig is easier to read.)
Connecting to the server from a client
From another computer on the same local area network, connect to the IP address of the machine on which x11vnc is running. Attempt to connect using a VNC client such as RealVNC, tightvnc, or remmina:
Creating a script that contains the x11vnc command line options
From a shell as the user that owns the Gnome desktop session, enter these commands:
cd ~
whoami
nano x11vncstartup.sh
Enter this text. Press Control-X to save and exit: