In this post, we create a Python script that connects to a Gmail inbox, extracts the text of the subject and body of each message, submits that text with a prompt to a large language model (LLM), then if conditions are met that match the prompt, escalates the message to the attention of an operator, based on a prompt.
Using an Ollama API server
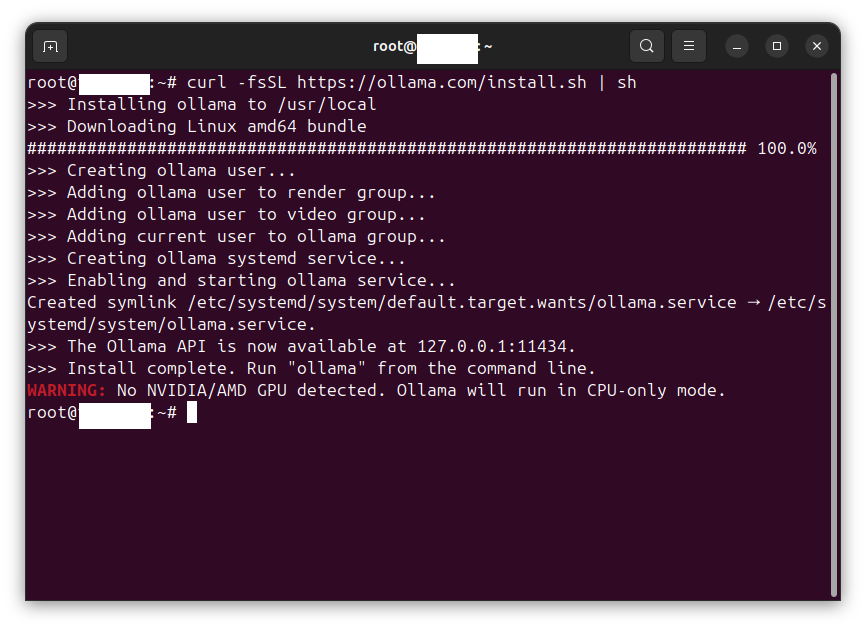
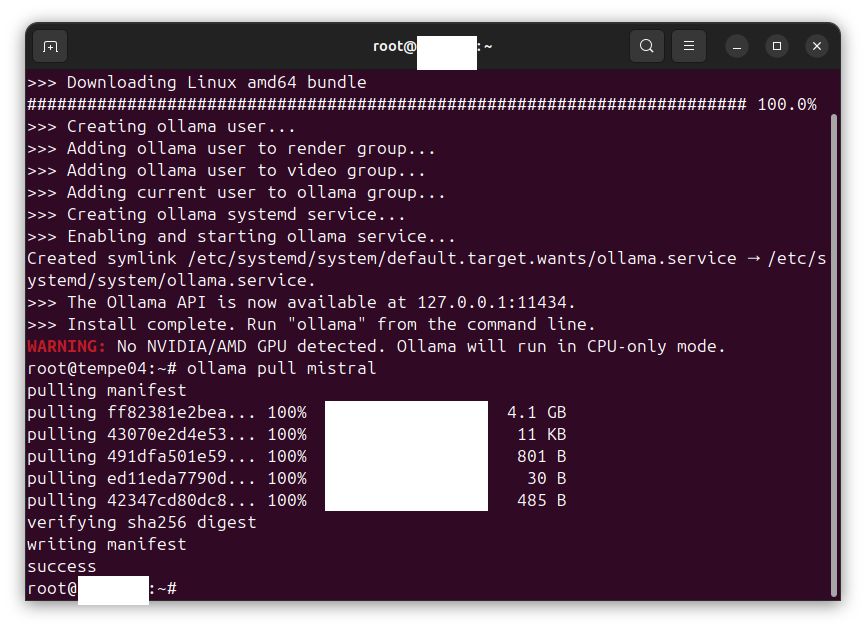
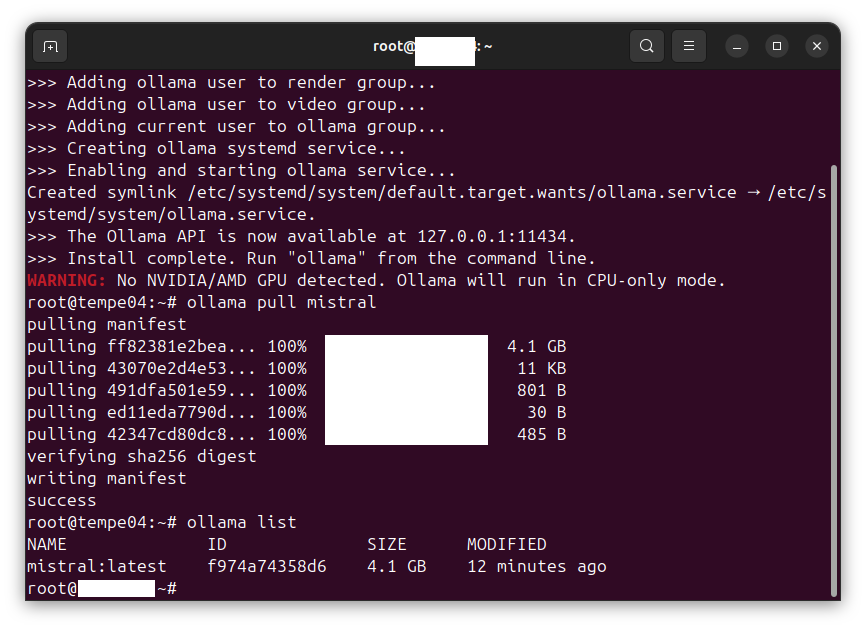
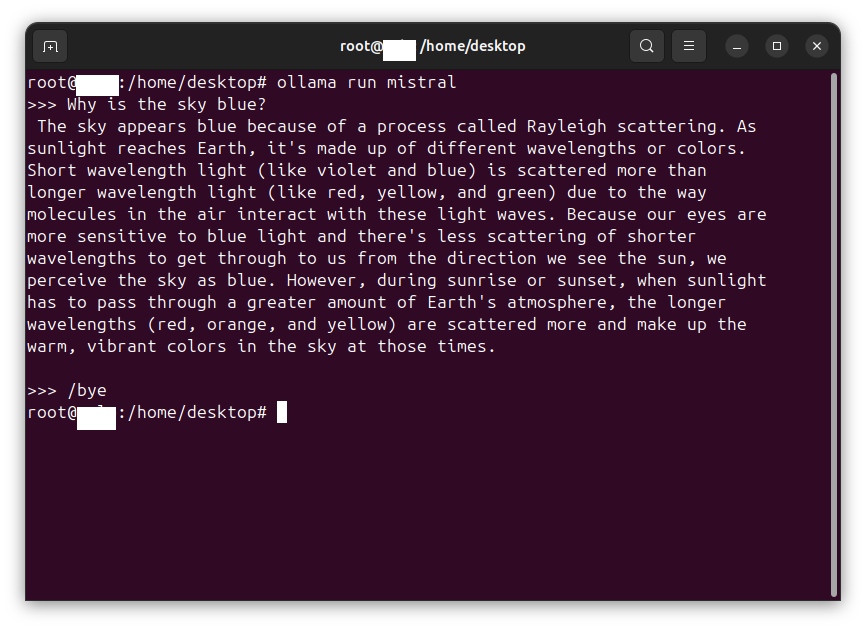
In this case, we are interacting with an Ollama LLM API server hosted locally. Refer to Using Ollama to host an LLM on CPU-only equipment to enable a local chatbot and LLM API server.
Using an OpenAI-compatible LLM API
An alternate source code listing is provided for an OpenAI-compatible LLM API.
Obtaining a Gmail app password
Visit the following site:
https://myaccount.google.com/apppasswords
Create a new app password. Take note of the password, it will not be visible again.
Note: Google adds spaces to the app password for readability. You should remove the spaces from the app password and use that value.
Escalating to the root user
In this procedure we run as the root user. Enter the following command:
Adding utilities to the operating system
Enter the following command:
apt install python3-venv python3-pip sqlite3
Creating a virtual environment and installing required packages with pip
Enter the following commands:
cd ~
mkdir doicareworkdir
cd doicareworkdir
python3 -m venv doicare_env
source doicare_env/bin/activate
pip install requests imaplib2
Creating the configuration file (config.json)
Enter the following command:
Use the nano editor to add the following text:
{
"gmail_user": "xxxxxxxxxxxx@xxxxx.xxx",
"gmail_app_password": "xxxxxxxxxxxxxxxx",
"api_base_url": "http://xxx.xxx.xxx.xxx:8085",
"openai_api_key": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"database": "doicare.db",
"scanasof": "18-Jan-2025",
"alert_recipients": [
"xxxxx@xxxxx.com"
],
"smtp_server": "smtp.gmail.com",
"smtp_port": 587,
"smtp_user": "xxxxxx@xxxxx.xxxxx",
"smtp_password": "xxxxxxxxxxxxxxxx",
"analysis_prompt": "Analyze the email below. If it needs escalation (urgent, sender upset, or critical issue), return 'Escalation Reason:' followed by one short sentence explaining why. If no escalation is needed, return exactly 'DOESNOTAPPLY'. Always provide either 'DOESNOTAPPLY' or a reason.",
"model": "mistral"
}
Save and exit the file.
Creating a Python script called doicare that connects to a Gmail inbox, submits messages to an LLM, and escalates messages based on a prompt (Ollama version)
Enter the following command:
nano doicare_gmail.py
import imaplib
import email
import sqlite3
import requests
import smtplib
import json
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import decode_header, make_header
# MIT license 2025 Gordon Buchan
# see https://opensource.org/licenses/MIT
# Some of this code was generated with the assistance of AI tools.
# --------------------------------------------------------------------
# 1. LOAD CONFIG
# --------------------------------------------------------------------
with open("config.json", "r") as cfg:
config = json.load(cfg)
GMAIL_USER = config["gmail_user"]
GMAIL_APP_PASSWORD = config["gmail_app_password"]
API_BASE_URL = config["api_base_url"]
OPENAI_API_KEY = config["openai_api_key"]
DATABASE = config["database"]
SCAN_ASOF = config["scanasof"]
ALERT_RECIPIENTS = config.get("alert_recipients", [])
SMTP_SERVER = config["smtp_server"]
SMTP_PORT = config["smtp_port"]
SMTP_USER = config["smtp_user"]
SMTP_PASSWORD = config["smtp_password"]
ANALYSIS_PROMPT = config["analysis_prompt"]
MODEL = config["model"]
# --------------------------------------------------------------------
# 2. DATABASE SETUP
# --------------------------------------------------------------------
def setup_database():
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS escalations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
email_date TEXT,
from_address TEXT,
to_address TEXT,
cc_address TEXT,
subject TEXT,
body TEXT,
reason TEXT,
created_at TEXT
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS scan_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
last_scanned_uid INTEGER
)
""")
conn.commit()
conn.close()
def get_last_scanned_uid():
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT last_scanned_uid FROM scan_info ORDER BY id DESC LIMIT 1")
row = cur.fetchone()
conn.close()
return row[0] if (row and row[0]) else 0
def update_last_scanned_uid(uid_val):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("INSERT INTO scan_info (last_scanned_uid) VALUES (?)", (uid_val,))
conn.commit()
conn.close()
def is_already_processed(uid_val):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT 1 FROM scan_info WHERE last_scanned_uid = ?", (uid_val,))
row = cur.fetchone()
conn.close()
return bool(row)
# --------------------------------------------------------------------
# 3. ANALYSIS & ALERTING
# --------------------------------------------------------------------
def analyze_with_openai(subject, body):
prompt = f"{ANALYSIS_PROMPT}\n\nSubject: {subject}\nBody: {body}"
url = f"{API_BASE_URL}/v1/completions"
headers = {"Content-Type": "application/json"}
if OPENAI_API_KEY:
headers["Authorization"] = f"Bearer {OPENAI_API_KEY}"
payload = {
"model": MODEL,
"prompt": prompt,
"max_tokens": 300,
"temperature": 0.7
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=60)
data = response.json()
if "error" in data:
print(f"[DEBUG] API Error: {data['error']['message']}")
return "DOESNOTAPPLY"
if "choices" in data and data["choices"]:
raw_text = data["choices"][0]["text"].strip()
return raw_text
return "DOESNOTAPPLY"
except Exception as e:
print(f"[DEBUG] Exception during API call: {e}")
return "DOESNOTAPPLY"
def send_alerts(reason, email_date, from_addr, to_addr, cc_addr, subject, body):
for recipient in ALERT_RECIPIENTS:
msg = MIMEMultipart()
msg["From"] = SMTP_USER
msg["To"] = recipient
msg["Subject"] = "Escalation Alert"
alert_text = f"""
Escalation Triggered
Date: {email_date}
From: {from_addr}
To: {to_addr}
CC: {cc_addr}
Subject: {subject}
Body: {body}
Reason: {reason}
"""
msg.attach(MIMEText(alert_text, "plain"))
try:
with smtplib.SMTP(SMTP_SERVER, SMTP_PORT) as server:
server.starttls()
server.login(SMTP_USER, SMTP_PASSWORD)
server.sendmail(SMTP_USER, recipient, msg.as_string())
print(f"Alert sent to {recipient}")
except Exception as ex:
print(f"Failed to send alert to {recipient}: {ex}")
def save_escalation(email_date, from_addr, to_addr, cc_addr, subject, body, reason):
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
INSERT INTO escalations (
email_date, from_address, to_address, cc_address,
subject, body, reason, created_at
) VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
email_date, from_addr, to_addr, cc_addr,
subject, body, reason, datetime.now().isoformat()
))
conn.commit()
conn.close()
# --------------------------------------------------------------------
# 4. MAIN LOGIC
# --------------------------------------------------------------------
def process_message(raw_email, uid_val):
parsed_msg = email.message_from_bytes(raw_email)
date_str = parsed_msg.get("Date", "")
from_addr = parsed_msg.get("From", "")
to_addr = parsed_msg.get("To", "")
cc_addr = parsed_msg.get("Cc", "")
subject_header = parsed_msg.get("Subject", "")
subject_decoded = str(make_header(decode_header(subject_header)))
body_text = ""
if parsed_msg.is_multipart():
for part in parsed_msg.walk():
ctype = part.get_content_type()
disposition = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in disposition:
charset = part.get_content_charset() or "utf-8"
body_text += part.get_payload(decode=True).decode(charset, errors="replace")
else:
charset = parsed_msg.get_content_charset() or "utf-8"
body_text = parsed_msg.get_payload(decode=True).decode(charset, errors="replace")
reason = analyze_with_openai(subject_decoded, body_text)
if "DOESNOTAPPLY" in reason:
print(f"[UID {uid_val}] No escalation: {reason}")
return
print(f"[UID {uid_val}] Escalation triggered: {subject_decoded[:50]}")
save_escalation(date_str, from_addr, to_addr, cc_addr, subject_decoded, body_text, reason)
send_alerts(reason, date_str, from_addr, to_addr, cc_addr, subject_decoded, body_text)
def main():
setup_database()
last_uid = get_last_scanned_uid()
print(f"[DEBUG] Retrieved last UID: {last_uid}")
try:
mail = imaplib.IMAP4_SSL("imap.gmail.com")
mail.login(GMAIL_USER, GMAIL_APP_PASSWORD)
print("IMAP login successful.")
except Exception as e:
print(f"Error logging into Gmail: {e}")
return
mail.select("INBOX")
if last_uid == 0:
print(f"[DEBUG] First run: scanning since date {SCAN_ASOF}")
r1, d1 = mail.search(None, f'(SINCE {SCAN_ASOF})')
else:
print(f"[DEBUG] Subsequent run: scanning for UIDs > {last_uid}")
r1, d1 = mail.uid('SEARCH', None, f'UID {last_uid + 1}:*')
if r1 != "OK":
print("[DEBUG] Search failed.")
mail.logout()
return
seq_nums = d1[0].split()
print(f"[DEBUG] Found {len(seq_nums)} messages to process: {seq_nums}")
if not seq_nums:
print("[DEBUG] No messages to process.")
mail.logout()
return
highest_uid_seen = last_uid
for seq_num in seq_nums:
if is_already_processed(seq_num.decode()):
print(f"[DEBUG] UID {seq_num.decode()} already processed, skipping.")
continue
print(f"[DEBUG] Processing sequence number: {seq_num}")
r2, d2 = mail.uid('FETCH', seq_num.decode(), '(RFC822)')
if r2 != "OK" or not d2 or len(d2) < 1 or not d2[0]:
print(f"[DEBUG] Failed to fetch message for UID {seq_num.decode()}")
continue
print(f"[DEBUG] Successfully fetched message for UID {seq_num.decode()}")
raw_email = d2[0][1]
try:
process_message(raw_email, int(seq_num.decode()))
mail.uid('STORE', seq_num.decode(), '+FLAGS', '\\Seen')
if int(seq_num.decode()) > highest_uid_seen:
highest_uid_seen = int(seq_num.decode())
except Exception as e:
print(f"[DEBUG] Error processing message UID {seq_num.decode()}: {e}")
if highest_uid_seen > last_uid:
print(f"[DEBUG] Updating last scanned UID to {highest_uid_seen}")
update_last_scanned_uid(highest_uid_seen)
mail.logout()
if __name__ == "__main__":
main()
Save and exit the file.
Creating a Python script called doicare that connects to a Gmail inbox, submits messages to an LLM, and escalates messages based on a prompt (OpenAI-compatible version)
Enter the following command:
nano doicare_gmail.py
import imaplib
import email
import sqlite3
import requests
import smtplib
import json
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import decode_header, make_header
# MIT license 2025 Gordon Buchan
# see https://opensource.org/licenses/MIT
# Some of this code was generated with the assistance of AI tools.
# --------------------------------------------------------------------
# 1. LOAD CONFIG
# --------------------------------------------------------------------
with open("config.json", "r") as cfg:
config = json.load(cfg)
GMAIL_USER = config["gmail_user"]
GMAIL_APP_PASSWORD = config["gmail_app_password"]
API_BASE_URL = config["api_base_url"]
OPENAI_API_KEY = config["openai_api_key"]
DATABASE = config["database"]
SCAN_ASOF = config["scanasof"]
ALERT_RECIPIENTS = config.get("alert_recipients", [])
SMTP_SERVER = config["smtp_server"]
SMTP_PORT = config["smtp_port"]
SMTP_USER = config["smtp_user"]
SMTP_PASSWORD = config["smtp_password"]
ANALYSIS_PROMPT = config["analysis_prompt"]
MODEL = config["model"]
# --------------------------------------------------------------------
# 2. DATABASE SETUP
# --------------------------------------------------------------------
def setup_database():
""" Ensure the database and necessary tables exist. """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
print("[DEBUG] Ensuring database tables exist...")
cur.execute("""
CREATE TABLE IF NOT EXISTS escalations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
email_date TEXT,
from_address TEXT,
to_address TEXT,
cc_address TEXT,
subject TEXT,
body TEXT,
reason TEXT,
created_at TEXT
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS scan_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
last_scanned_uid INTEGER UNIQUE
)
""")
# Ensure at least one row exists in scan_info
cur.execute("SELECT COUNT(*) FROM scan_info")
if cur.fetchone()[0] == 0:
cur.execute("INSERT INTO scan_info (last_scanned_uid) VALUES (0)")
conn.commit()
conn.close()
print("[DEBUG] Database setup complete.")
def get_last_scanned_uid():
""" Retrieve the last scanned UID from the database """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("SELECT last_scanned_uid FROM scan_info ORDER BY id DESC LIMIT 1")
row = cur.fetchone()
conn.close()
return int(row[0]) if (row and row[0]) else 0
def update_last_scanned_uid(uid_val):
""" Update the last scanned UID in the database """
conn = sqlite3.connect(DATABASE)
cur = conn.cursor()
cur.execute("""
INSERT INTO scan_info (id, last_scanned_uid)
VALUES (1, ?)
ON CONFLICT(id) DO UPDATE SET last_scanned_uid = excluded.last_scanned_uid
""", (uid_val,))
conn.commit()
conn.close()
# --------------------------------------------------------------------
# 3. ANALYSIS & ALERTING
# --------------------------------------------------------------------
def analyze_with_openai(subject, body):
""" Send email content to OpenAI API for analysis """
prompt = f"{ANALYSIS_PROMPT}\n\nSubject: {subject}\nBody: {body}"
url = f"{API_BASE_URL}/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {OPENAI_API_KEY}" if OPENAI_API_KEY else "",
}
payload = {
"model": MODEL,
"messages": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": prompt}
],
"max_tokens": 300,
"temperature": 0.7
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=60)
data = response.json()
if "error" in data:
print(f"[DEBUG] API Error: {data['error']['message']}")
return "DOESNOTAPPLY"
if "choices" in data and data["choices"]:
return data["choices"][0]["message"]["content"].strip()
return "DOESNOTAPPLY"
except Exception as e:
print(f"[DEBUG] Exception during API call: {e}")
return "DOESNOTAPPLY"
# --------------------------------------------------------------------
# 4. MAIN LOGIC
# --------------------------------------------------------------------
def process_message(raw_email, uid_val):
""" Process a single email message """
parsed_msg = email.message_from_bytes(raw_email)
date_str = parsed_msg.get("Date", "")
from_addr = parsed_msg.get("From", "")
to_addr = parsed_msg.get("To", "")
cc_addr = parsed_msg.get("Cc", "")
subject_header = parsed_msg.get("Subject", "")
subject_decoded = str(make_header(decode_header(subject_header)))
body_text = ""
if parsed_msg.is_multipart():
for part in parsed_msg.walk():
ctype = part.get_content_type()
disposition = str(part.get("Content-Disposition"))
if ctype == "text/plain" and "attachment" not in disposition:
charset = part.get_content_charset() or "utf-8"
body_text += part.get_payload(decode=True).decode(charset, errors="replace")
else:
charset = parsed_msg.get_content_charset() or "utf-8"
body_text = parsed_msg.get_payload(decode=True).decode(charset, errors="replace")
reason = analyze_with_openai(subject_decoded, body_text)
if "DOESNOTAPPLY" in reason:
print(f"[UID {uid_val}] No escalation: {reason}")
return
print(f"[UID {uid_val}] Escalation triggered: {subject_decoded[:50]}")
update_last_scanned_uid(uid_val)
def main():
""" Main function to fetch and process emails """
setup_database()
last_uid = get_last_scanned_uid()
print(f"[DEBUG] Retrieved last UID: {last_uid}")
try:
mail = imaplib.IMAP4_SSL("imap.gmail.com")
mail.login(GMAIL_USER, GMAIL_APP_PASSWORD)
print("IMAP login successful.")
except Exception as e:
print(f"Error logging into Gmail: {e}")
return
mail.select("INBOX")
search_query = f'UID {last_uid + 1}:*' if last_uid > 0 else f'SINCE {SCAN_ASOF}'
print(f"[DEBUG] Running IMAP search: {search_query}")
r1, d1 = mail.uid('SEARCH', None, search_query)
if r1 != "OK":
print("[DEBUG] Search failed.")
mail.logout()
return
seq_nums = d1[0].split()
seq_nums = [seq.decode() for seq in seq_nums]
print(f"[DEBUG] Found {len(seq_nums)} new messages: {seq_nums}")
if not seq_nums:
print("[DEBUG] No new messages found, exiting.")
mail.logout()
return
highest_uid_seen = last_uid
for seq_num in seq_nums:
numeric_uid = int(seq_num)
if numeric_uid <= last_uid:
print(f"[DEBUG] UID {numeric_uid} already processed, skipping.")
continue
print(f"[DEBUG] Processing UID: {numeric_uid}")
r2, d2 = mail.uid('FETCH', seq_num, '(RFC822)')
if r2 != "OK" or not d2 or len(d2) < 1 or not d2[0]:
print(f"[DEBUG] Failed to fetch message for UID {numeric_uid}")
continue
raw_email = d2[0][1]
process_message(raw_email, numeric_uid)
highest_uid_seen = max(highest_uid_seen, numeric_uid)
if highest_uid_seen > last_uid:
print(f"[DEBUG] Updating last scanned UID to {highest_uid_seen}")
update_last_scanned_uid(highest_uid_seen)
mail.logout()
if __name__ == "__main__":
main()
Save and exit the file.
Running the doicare_gmail.py script
Enter the following command:
Sample output
(doicare_env) root@xxxxx:/home/desktop/doicareworkingdir# python3 doicare_gmail.py
[DEBUG] Retrieved last UID: 0
IMAP login successful.
[DEBUG] First run: scanning since date 18-Jan-2025
[DEBUG] Found 23 messages to process: [b'49146', b'49147', b'49148', b'49149', b'49150', b'49151', b'49152', b'49153', b'49154', b'49155', b'49156', b'49157', b'49158', b'49159', b'49160', b'49161', b'49162', b'49163', b'49164', b'49165', b'49166', b'49167', b'49168']
[DEBUG] Processing sequence number: b'49146'
[DEBUG] FETCH response: b'49146 (UID 50196)'
[DEBUG] FETCH line to parse: 49146 (UID 50196)
[DEBUG] Parsed UID: 50196
[DEBUG] Valid UID Found: 50196
[DEBUG] Successfully fetched message for UID 50196
[UID 50196] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, sender is not upset, and there does not seem to be a critical issue mentioned.
[DEBUG] Processing sequence number: b'49147'
[DEBUG] FETCH response: b'49147 (UID 50197)'
[DEBUG] FETCH line to parse: 49147 (UID 50197)
[DEBUG] Parsed UID: 50197
[DEBUG] Valid UID Found: 50197
[DEBUG] Successfully fetched message for UID 50197
[UID 50197] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49148'
[DEBUG] FETCH response: b'49148 (UID 50198)'
[DEBUG] FETCH line to parse: 49148 (UID 50198)
[DEBUG] Parsed UID: 50198
[DEBUG] Valid UID Found: 50198
[DEBUG] Successfully fetched message for UID 50198
[UID 50198] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, sender is not upset, and there doesn't seem to be a critical issue presented in the content.
[DEBUG] Processing sequence number: b'49149'
[DEBUG] FETCH response: b'49149 (UID 50199)'
[DEBUG] FETCH line to parse: 49149 (UID 50199)
[DEBUG] Parsed UID: 50199
[DEBUG] Valid UID Found: 50199
[DEBUG] Successfully fetched message for UID 50199
[UID 50199] No escalation: DOESNOTAPPLY. The email does not contain any urgent matter, the sender is not upset, and there is no critical issue mentioned in the message.
[DEBUG] Processing sequence number: b'49150'
[DEBUG] FETCH response: b'49150 (UID 50200)'
[DEBUG] FETCH line to parse: 49150 (UID 50200)
[DEBUG] Parsed UID: 50200
[DEBUG] Valid UID Found: 50200
[DEBUG] Successfully fetched message for UID 50200
[UID 50200] No escalation: DOESNOTAPPLY. The email lacks sufficient content for an escalation.
[DEBUG] Processing sequence number: b'49151'
[DEBUG] FETCH response: b'49151 (UID 50201)'
[DEBUG] FETCH line to parse: 49151 (UID 50201)
[DEBUG] Parsed UID: 50201
[DEBUG] Valid UID Found: 50201
[DEBUG] Successfully fetched message for UID 50201
[UID 50201] Escalation triggered: Security alert
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49152'
[DEBUG] FETCH response: b'49152 (UID 50202)'
[DEBUG] FETCH line to parse: 49152 (UID 50202)
[DEBUG] Parsed UID: 50202
[DEBUG] Valid UID Found: 50202
[DEBUG] Successfully fetched message for UID 50202
[UID 50202] Escalation triggered: Delivery Status Notification (Failure)
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49153'
[DEBUG] FETCH response: b'49153 (UID 50203)'
[DEBUG] FETCH line to parse: 49153 (UID 50203)
[DEBUG] Parsed UID: 50203
[DEBUG] Valid UID Found: 50203
[DEBUG] Successfully fetched message for UID 50203
[UID 50203] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49154'
[DEBUG] FETCH response: b'49154 (UID 50204)'
[DEBUG] FETCH line to parse: 49154 (UID 50204)
[DEBUG] Parsed UID: 50204
[DEBUG] Valid UID Found: 50204
[DEBUG] Successfully fetched message for UID 50204
[UID 50204] Escalation triggered: my server lollipop is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49155'
[DEBUG] FETCH response: b'49155 (UID 50205)'
[DEBUG] FETCH line to parse: 49155 (UID 50205)
[DEBUG] Parsed UID: 50205
[DEBUG] Valid UID Found: 50205
[DEBUG] Successfully fetched message for UID 50205
[UID 50205] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49156'
[DEBUG] FETCH response: b'49156 (UID 50206)'
[DEBUG] FETCH line to parse: 49156 (UID 50206)
[DEBUG] Parsed UID: 50206
[DEBUG] Valid UID Found: 50206
[DEBUG] Successfully fetched message for UID 50206
[UID 50206] Escalation triggered: now doomfire is down too!
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49157'
[DEBUG] FETCH response: b'49157 (UID 50207)'
[DEBUG] FETCH line to parse: 49157 (UID 50207)
[DEBUG] Parsed UID: 50207
[DEBUG] Valid UID Found: 50207
[DEBUG] Successfully fetched message for UID 50207
[UID 50207] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49158'
[DEBUG] FETCH response: b'49158 (UID 50208)'
[DEBUG] FETCH line to parse: 49158 (UID 50208)
[DEBUG] Parsed UID: 50208
[DEBUG] Valid UID Found: 50208
[DEBUG] Successfully fetched message for UID 50208
[UID 50208] Escalation triggered: pants is down now
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49159'
[DEBUG] FETCH response: b'49159 (UID 50209)'
[DEBUG] FETCH line to parse: 49159 (UID 50209)
[DEBUG] Parsed UID: 50209
[DEBUG] Valid UID Found: 50209
[DEBUG] Successfully fetched message for UID 50209
[UID 50209] Escalation triggered: server05 down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49160'
[DEBUG] FETCH response: b'49160 (UID 50210)'
[DEBUG] FETCH line to parse: 49160 (UID 50210)
[DEBUG] Parsed UID: 50210
[DEBUG] Valid UID Found: 50210
[DEBUG] Successfully fetched message for UID 50210
[UID 50210] No escalation: DOESNOTAPPLY (The sender has asked for a phone call instead of specifying the issue in detail, so it doesn't appear to be urgent or critical at first glance.)
[DEBUG] Processing sequence number: b'49161'
[DEBUG] FETCH response: b'49161 (UID 50211)'
[DEBUG] FETCH line to parse: 49161 (UID 50211)
[DEBUG] Parsed UID: 50211
[DEBUG] Valid UID Found: 50211
[DEBUG] Successfully fetched message for UID 50211
[UID 50211] Escalation triggered: my server is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49162'
[DEBUG] FETCH response: b'49162 (UID 50212)'
[DEBUG] FETCH line to parse: 49162 (UID 50212)
[DEBUG] Parsed UID: 50212
[DEBUG] Valid UID Found: 50212
[DEBUG] Successfully fetched message for UID 50212
[UID 50212] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49163'
[DEBUG] FETCH response: b'49163 (UID 50213)'
[DEBUG] FETCH line to parse: 49163 (UID 50213)
[DEBUG] Parsed UID: 50213
[DEBUG] Valid UID Found: 50213
[DEBUG] Successfully fetched message for UID 50213
[UID 50213] Escalation triggered: this is getting bad
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49164'
[DEBUG] FETCH response: b'49164 (UID 50214)'
[DEBUG] FETCH line to parse: 49164 (UID 50214)
[DEBUG] Parsed UID: 50214
[DEBUG] Valid UID Found: 50214
[DEBUG] Successfully fetched message for UID 50214
[UID 50214] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49165'
[DEBUG] FETCH response: b'49165 (UID 50215)'
[DEBUG] FETCH line to parse: 49165 (UID 50215)
[DEBUG] Parsed UID: 50215
[DEBUG] Valid UID Found: 50215
[DEBUG] Successfully fetched message for UID 50215
[UID 50215] Escalation triggered: server zebra 05 is down
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49166'
[DEBUG] FETCH response: b'49166 (UID 50216)'
[DEBUG] FETCH line to parse: 49166 (UID 50216)
[DEBUG] Parsed UID: 50216
[DEBUG] Valid UID Found: 50216
[DEBUG] Successfully fetched message for UID 50216
[UID 50216] No escalation: DOESNOTAPPLY
[DEBUG] Processing sequence number: b'49167'
[DEBUG] FETCH response: b'49167 (UID 50217)'
[DEBUG] FETCH line to parse: 49167 (UID 50217)
[DEBUG] Parsed UID: 50217
[DEBUG] Valid UID Found: 50217
[DEBUG] Successfully fetched message for UID 50217
[UID 50217] Escalation triggered: help
Alert sent to xxxx@hotmail.com
[DEBUG] Processing sequence number: b'49168'
[DEBUG] FETCH response: b'49168 (UID 50218)'
[DEBUG] FETCH line to parse: 49168 (UID 50218)
[DEBUG] Parsed UID: 50218
[DEBUG] Valid UID Found: 50218
[DEBUG] Successfully fetched message for UID 50218
[UID 50218] Escalation triggered: server is down
Alert sent to xxxx@hotmail.com
[DEBUG] Updating last scanned UID to 50218
[DEBUG] Attempting to update last scanned UID to 50218
[DEBUG] Last scanned UID successfully updated to 50218
Example of an alert message
Escalation Triggered
Date: Sat, 18 Jan 2025 21:00:16 +0000
From: Gordon Buchan <gordonhbuchan@hotmail.com>
To: "gordonhbuchan@gmail.com" <gordonhbuchan@gmail.com>
CC:
Subject: server is down
Body: server down help please
Reason: Escalation Reason: This email indicates that there is a critical issue (server downtime).
Creating a systemd service to run the doicare script automatically
Enter the following command:
nano /etc/systemd/system/doicare.service
Use the nano editor to add the following text (change values to match your path):
[Unit]
Description=Run all monitoring tasks
[Service]
Type=oneshot
WorkingDirectory=/root/doicareworkdir
ExecStart=/usr/bin/bash -c "source /root/doicareworkdir/doicare_env/bin/activate && python3 doicare_gmail.py"
Save and exit the file.
Creating a systemd timer to run the doicare script automatically
Enter the following command:
nano /etc/systemd/system/doicare.timer
Use the nano editor to add the following text:
[Unit]
Description=Run monitoring tasks every 5 minutes
[Timer]
OnBootSec=5min
OnUnitActiveSec=5min
[Install]
WantedBy=timers.target
Save and exit the file.
Enabling the doicare service
Enter the following commands:
systemctl daemon-reload
systemctl start doicare.service
systemctl enable doicare.service
systemctl start doicare.timer
systemctl enable doicare.timer